
Today, I will introduce a common process model to organize an ML project - the CRISP-DM process model. After that, I will present a simple ML lifecycle and the four-phased of ML adoption.
The CRISP-DM process model
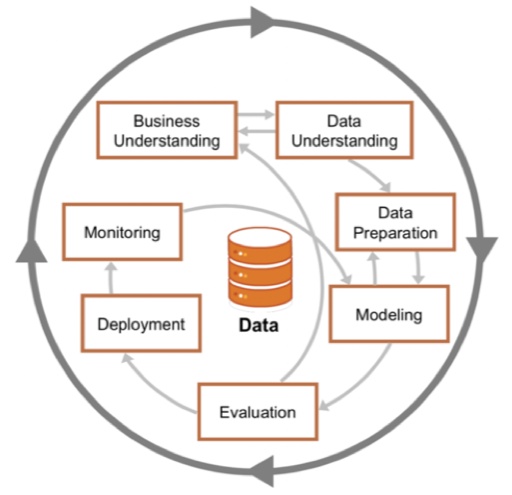
CRISP-DM - CRoss Industry Standard Process for Data Mining - is a process model that helps you plan, organize, and implement your ML project. It includes six phases that describe the data science life cycle as below:
- Business understanding
- Data understanding
- Data preparation
- Modeling
- Evaluation
- Deployment
Business understanding
At the very beginning, we need to scope the project by laying out goals and objectives, constraints, and evaluation criteria. Stakeholders should be identified and involved. Resources should be estimated and allocated. This stage is also the place for business analysis, where model performance needs to be evaluated against business goals and analyzed to generate business insights. These insights can then be used to eliminate unproductive projects or scope new projects. We need to do these four steps:
- Understand business requirements
- Form a business question
- Highlight the project's critical features
- Analyze supporting information
- List required resources and assumptions
- Analyze associated risks
- Plan for contingencies
- Compare costs and benefits
- Convert to ML objective
- Review ML question
- Create technical data mining objective
- Define the criteria for the successful outcome of the project
- Create a project plan
- Number and duration of stages
- Dependencies
- Risks
- Goals
- Evaluation methods
- Tools and techniques
We will discuss this in more detail in the future post.
Data understanding
In this phase, we need to complete these three steps:
- Collect data
- Detail various sources and steps to extract data
- Analyze data for additional requirements
- Consider other data sources
- Understand data
- Describe data, amount of data used, and metadata properties
- Find key features and relationships in the data
- Use tools and techniques to explore data properties
- Verify data quality
- Verify features
- Identify data quality issues mentioned in the post
- Report solution
The amount of data used and generated by an ML system can be large and diverse. A scalable infrastructure is required to process and access the data quickly and reliably.
Data preparation
In this phase, we will complete two steps:
- Select the final dataset
- Define size
- Included/Excluded features
- Select rows/records
- Define the data type
- Prepare the data:
- Clean: solve data quality issues
- Transform: derive additional features from original ones, normalize, transform features
- Merge: merge features
- Format: rearrange features, shuffle data, format Unicode if needed
After this phase, we can go back to the Data Understanding phase to understand and recheck the data.
Modeling
This stage is where you perform model exploration, model training, and model testing. In this phase, we need to perform three main steps:
- Select and create the model
- Select modeling technique
- Identify constraints of the technique and tools
- Identify how those constraints tie back to the Data preparation phase
- Build test plan
- Split data
- Identify evaluation criteria
- Build model
- Train model
- Tweak model for better performance
- Build multiple models with different parameter settings
- Describe the trained models and report on the findings
Note that this phase works together with the Data preparation phase.
Evaluation
In this phase, we will complete three steps:
- Evaluate model performance
- Evaluation criteria
- Model generalization on unseen data
- Business success criteria
- Review process
- Assess the steps in each phase: Was anything overlooked? Were all steps properly executed?
- Perform quality assurance checks: Summarize findings and correct anything if needed.
- Determine the next step
- Decide to deploy to production
- Or iterate the current project
- Or start a new project
Deployment
After a model is ready to be used, a deployment infrastructure should be ready to make the model accessible to users. Once in production, we need to monitor and maintain data quality and model quality to detect their decay as soon as possible to adapt to changing environments and requirements. In this phase, we need to complete these four steps:
- Plan deployment
- Develop, and document a plan for deployment
- Maintain and monitor
- Develop a plan for maintenance and monitoring data quality, model quality
- Produce final report
- Highlight processes used in the project
- Analyze if all the goals were met
- Report findings
- Identify and explain the model used and the reason behind using the model
- Identify the customer groups to target using this model
- Review project: Assess the outcomes of the project
- Summarize results and write documents about common pitfalls, and choose the right ML solution
- Generalize the whole process to make it useful for the next iteration
The Machine Learning lifecycle
I prefer to do things in simple ways. The data understanding and data preparation steps can be combined into one data engineering step; the modeling and evaluation steps can be combined into one model development step. So now, we have four main phases:
- Problem definition (Business understanding)
- Data engineering
- Model development
- Deployment
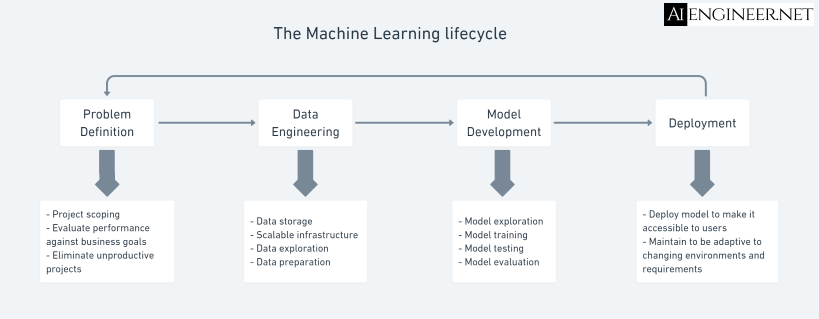
In reality, you can split these four phases into small steps depending on the scale of your ML project and the current stage of the ML adoption process at your organization.
Four phases of ML adoption

Once you decide to adopt ML into your project, your strategy depends on which phase of ML adoption you are in. Below are the four phases of adopting ML, with solutions from each phase that can be used as baselines to evaluate the solutions from the next phase.
1. Before ML
You should start with non-ML solutions.
"If you think that machine learning will give you a 100% boost, then a heuristic will get you 50% of the way there." - Martin Zinkevich in Rules of Machine Learning: Best Practices for ML Engineering
2. Simplest ML models
At this stage, you should start with simple algorithms. E.g., Logistic regression XGBoost, K-nearest neighbors, etc.
This stage allows you to quickly build out a framework from data management from development to deployment that you can test and trust.
3. Optimize simple models
Optimize simple ML models with different objective functions, hyperparameter search, feature engineering, more data, ensembles, etc.
This stage lets you answer questions like how quickly your model decays in production and update your infrastructure accordingly.
4. Complex systems
After you reached the limit of simple models and your use case demands significant model improvement.
Ending
Some people define the ML lifecycle differently, but in general, things happen around four pillars: problem definition, data engineering, ML model development, and deployment. I do make it simple, but I don't oversimplify it.