
"We believe it's better to have application programmers deal with performance problems due to overuse of transactions as bottleneck arise, rather than always coding around the lack of transactions." - Google's Spanner distributed database paper
One one hand, eventually consistent databases are designed to scale by allowing data to be partitioned and replicated across multiple machines. On the other hand, strongly consistent databases are designed to ensure that all clients see consistent values once they have been updated.
The challenge lies in providing the benefits of strongly consistent databases, such as guaranteed consistency of updates and no data loss or corruption, while also achieving the performance and availability advantages of eventually consistent systems.
Introduction
Strong consistency guarantees that once an update is confirmed, all subsequent reads will see the new value. If concurrent writes occur to the same object, the updates are treated as if they happened sequentially, with no data loss or corruption.
There are two concepts that need to be distinguished, as follows:
| Concept | Definition |
|---|---|
| Transactional consistency | Refers to the C in ACID transactions (opens in a new tab) supported by relational databases. In this case, consistency is determined by the semantics of the business logic executed within the transaction |
| Replica consistency | Ensures that all clients see the same value for an object after it is updated. There is no window of inconsistency, as in eventually consistent databases |
The algorithms utilized for both transactional and replica consistency are known as consensus algorithms. In the case of transactional consistency, all participants in the transaction must reach an agreement to either commit or abort the changes. For replica consistency, all replicas must agree on the same order of updates.
Consistency models
There have been several consistency models invented over the past few decades. This section will describe the 2 strongest consistency models.
| Model | Definition |
|---|---|
| Serializability | Refers to the C in ACID transactions, where multiple reads and writes can be performed on multiple objects, guaranteeing that concurrent transactions over multiple items occur sequentially |
| Linearizability | Referred to the C in CAP theorem. All clients should always see the latest update |
The combination of these 2 models results in the strongest possible data consistency, known as strong consistency.
Distributed transactions
Consistency models in distributed relational databases require consensus algorithms, with the most common one being the 2-phase commit (2PC) algorithm.
2-phase commit
In the 2-phase commit (2PC) algorithm, a leader, which can be an external service or an internal database service, controls the process. In a distributed relational database, the leader can be one of the partitions being updated.
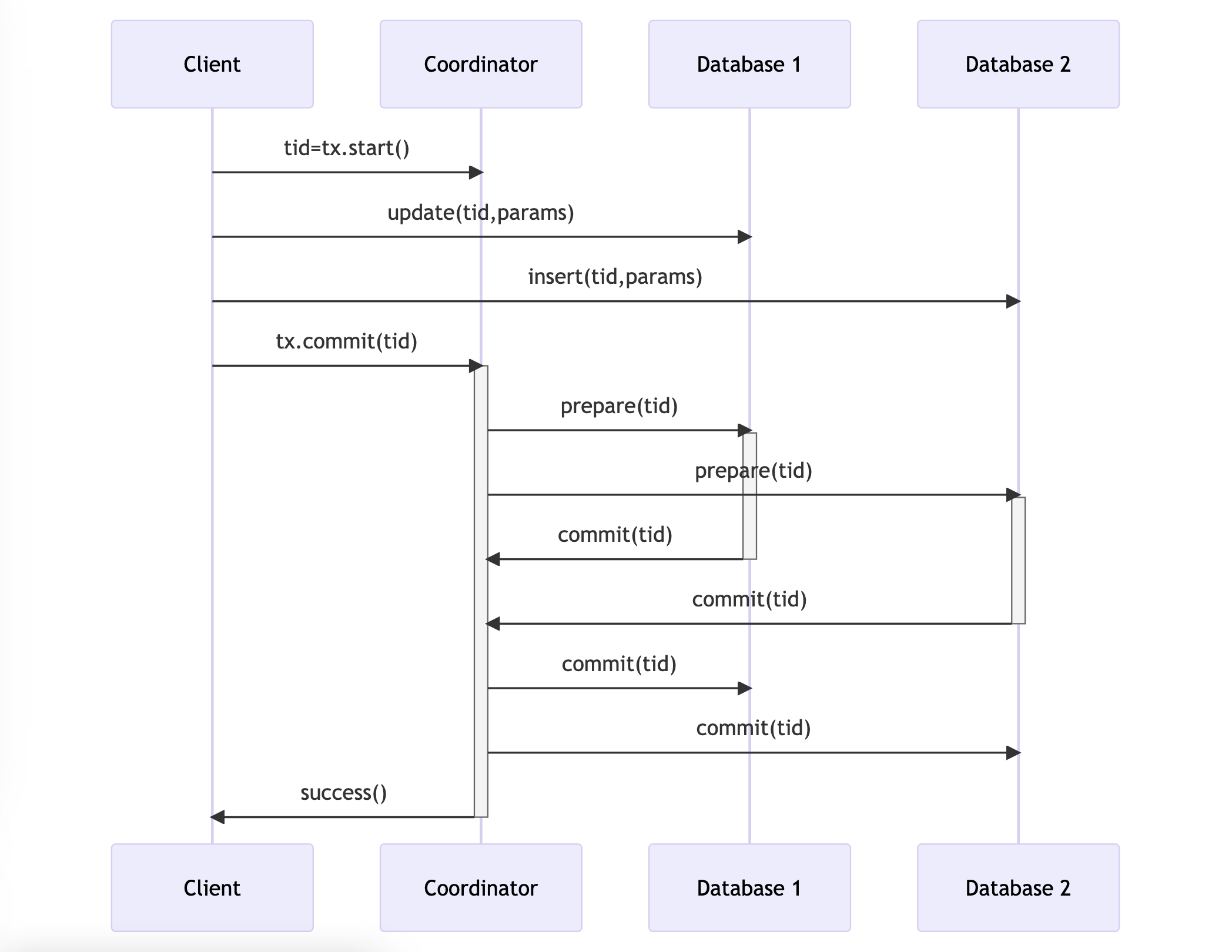
The workflow of a transaction is as follows:
- A client starts a transaction and a leader is selected. The leader returns a globally unique transaction ID (tid), which identifies a data structure known as the transaction context maintained by the leader. The transaction context records the participating database partitions and their communication state
- The client executes the operations defined by the transaction, passing the tid to each participant. Each participant acquires locks on mutated objects and executes the operations locally, but the database updates are not completed
- After all operations in each participant are completed, the client tries to commit the transaction, triggering the 2PC algorithm with a Prepare phase and a Resolve phase
- Prepare phase: The leader sends a message to all participants, instructing them to prepare to commit. If a participant prepares successfully, it guarantees that it can commit the transaction, and it cannot abort the transaction after this point. Otherwise, it must abort
- Resolve phase: If all participants can commit, the transaction is committed, and the leader sends a commit message to each participant. Otherwise, if any participant cannot commit, the transaction is aborted, and the leader sends an abort message to each participant
2-phase commit failures
There are 2 main types of failures that can occur from participants or the leader.
Participant failure
If a participant crashes before the prepare phase, the transaction is aborted. If a participant crashes after a successful prepare phase, the transaction is still successful. In both cases, after the participant restarts, it needs to request the leader for the transaction outcome to complete the transaction locally. Participant failure does not affect consistency, as the correct transaction outcome is still reached.
Leader failure
If the leader fails after the prepare phase, participants that have already replied to commit are blocked until the leader informs them of the transaction outcome. If the leader fails before or during the resolve phase, participants cannot proceed until the leader recovers.
The only practical solution is for participants to wait until the leader recovers and instructs them on the next steps. The leader recovery time is likely to be at least a few seconds, impacting availability. Moreover, other concurrent transactions cannot proceed as participants are holding locks on the mutated data. This is the weakness of 2PC when it does not tolerate leader failure, as the leader becomes a single point of failure.
One possible solution to address the single point of failure issue is to replicate the leader and transaction state across participants. If the leader fails, participants can elect a new leader to complete the transaction. This leads to the implementation of distributed consensus algorithms, such as the Raft algorithm (opens in a new tab).
Keynotes
-
Strong consistency models ensure that all nodes see the same data at the same time, while eventual consistency models allow for temporary inconsistencies
-
Distributed transactions are used to maintain consistency across multiple nodes in a distributed system. The 2-phase commit protocol is a common approach to distributed transactions, where a coordinator node ensures that all nodes agree to commit or abort a transaction
-
The 2-phase commit protocol can fail in various ways, such as network failures, node failures, or coordinator failures. These failures can result in transaction delays or data inconsistencies. Various techniques can be used to mitigate these failures, such as timeouts, retries, and replica synchronization