
This post will discuss the differences between ML in research and ML in production, between traditional software and ML systems, some ML challenges in production, and some ML deployment myths. This information will help you set the right expectation for your ML project.
Research vs. Production
The table below shows five significant problems and the differences between ML systems in research and production.
| Research | Production | |
|---|---|---|
| Objectives | Model performance | Different stakeholders have different objectives |
| Computational priority | Fast training, high throughput | Fast inference, low latency |
| Data | Static | Constantly shifting |
| Fairness | Good to have (sadly) | Important |
| Interpretability | Good to have | Important |
Objective

In academia, the objective of an ML system usually is model performance. Researchers want to achieve state-of-the-art results on benchmark datasets. Models often are too complicated to be helpful in real-life applications.
Different stakeholders have different objectives. For example, Facebook wants to train a model that recommends ads on users' news feed:
- ML engineers want that model to predict ads with a high chance of being clicked by users.
- Sales team wants that model predicts ads paid with the highest advertising fee to be shown in the user's news feed.
- Manager wants to maximize the profit, maybe by sacking somebody.
Users won't see the difference between a model with 98% accuracy and a model with 98.2% accuracy. This 0.2% can save Google millions of dollars.
If a simple model can do a reasonable job, complex models must perform significantly better to justify the complexity.
Computational priority
In research, we want the training process faster. In production, we want the inference faster.
In research, we want the training process to take as many samples as possible in a second (throughput). In production, latency matters a lot. If you can type your next word faster than your iPhone predicts, do you ever want to wait and click on the predicted word?
Data
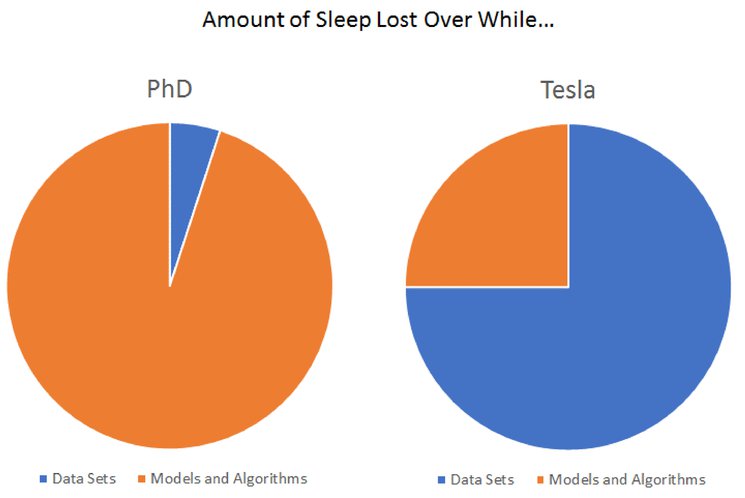
In research, data is clean and formatted. They are unchanged, so people can use them as benchmarks for evaluation. The process of preparing data and feeding it to your model usually was done by somebody.
In production, data is messy. You have to clean it and re-format it. It's not easy to split into the training set, test set, or validation set because it usually has issues like biased, imbalanced, outdated, etc. Sometimes you have to add more label classes or merge two existing label classes. This is a nightmare!
In research, data usually was created a long time ago. Data could be created a long time ago, streaming data, or both in production. In production, you need to care about data privacy and regulations.
| Research | Production |
|---|---|
| Clean | Messy |
| Static | Constantly shifting |
| Mostly historical data | Historical + streaming data |
| Privacy + regulatory concerns |
Fairness
You might be a victim of biased ML algorithms. Your resume might be ranked very low because your name is not common. The ranking model picks name as an important feature :)
ML algorithms don't predict the future but encode the past, perpetuating the biases in the data and more.
The minority groups would be harmed badly because the wrong predictions have minor consequences on the model's overall performance.
Interpretability
Model interpretability is important to understand why the model makes that prediction/decision. Otherwise, we might feel uncomfortable trusting it. It also makes debugging, monitoring, and improving the model easier.
While most of us are comfortable using a microwave without understanding how it works, many don't feel the same way about AI yet, especially if that AI makes important decisions about their lives.
Addons
Most companies cannot pursue pure research unless it leads to short-term profitable applications.
Nowadays, more people and organizations in different fields want to find applications due to the easy accessibility of state-of-the-art models. That's why the majority of ML-related jobs are in ML production.
Traditional software vs. ML systems
ML production would be a better place if ML experts were better software engineers. Many traditional software engineering tools can be used to develop and deploy ML applications.
However, many challenges are unique to ML applications and require their own tools. Below is the table to compare traditional software and ML systems.
| Traditional software | ML systems | |
|---|---|---|
| Code & data | Are separated | Part code, part data |
| Testing & versioning | Test and version code | Test and version code & data, models |
| Size | Data & code are not too big | Model size might be a challenge |
| Monitor & debug | A good logging system might be enough | Not-trivial |
ML production challenges
The table below shows some common challenges in ML production.
| # | Challenge | Description | Example |
|---|---|---|---|
| 1 | Data labeling | Quickly label new data or re-label existing data for a new model? | Snorkel |
| 2 | Data testing | Test the usefulness and correctness of data? Is a sample good or bad for your system? | |
| 3 | Data and model versioning | Version datasets and checkpoints? Merge different versions of data | DVC |
| 4 | Data format | Take out a subset of features in datasets -> use column-based data format (e.g., PARQUET, ORC). Row-based data formats (CSV) require loading all features | |
| 5 | Data manipulation | DataFrames designed for parallelization and compatible with GPUs as pandas doesn't work on GPUs | dask |
| 6 | Monitoring | Has data distribution shifted? Do we need to retrain? | Dessa |
| 7 | Model compression | Compress model to fit onto consumer devices? | Xnor.ai |
| 8 | Deployment | Package and deploy new model or replace existing model? | OctoML |
| 9 | CI/CD test | Run tests after each change of new model? | Argo |
| 10 | Inference optimization | Speed up inference time? Can we fuse operations? Can we use lower precision? | TensorRT |
| 11 | Edge device | Hardware designed to run ML algorithms fast and cheap? | Coral SOM |
| 12 | Privacy | Use user data while preserving their privacy? Make your process GDPR-compliant? | PySyft |
ML deployment myths

The table below summarizes some common ML deployment myths.
| # | Myth | Description |
|---|---|---|
| 1 | Deploying is hard | Deploying is easy; deploying reliable is hard. Making the model available to millions of users with a latency of milliseconds and 99% uptime is hard |
| 2 | Only deploy one or two ML models at a time | Companies have many ML models. Each different feature of an application requires its own model |
| 3 | If we don't do anything, model performance remains the same | Drift concept: the data your model runs inference on drifts further and further away from the data it was trained on. ML sys performs best right after training |
| 4 | No need to update models as much | Since a model performance decays over time, we want to update it as fast as possible |
| 5 | No need to worry about scale | E.g., a system that serves hundreds of queries per second or millions of users per month |
| 6 | ML can transform the business overnight | Magically - possible, but overnight - no. The longer you've adopted ML, the faster your development cycle will run, and the higher your Returns On Investment (ROI) will be |
Case studies
To end this post, these are some helpful case studies that might help you to see how actual teams deal with different deployment requirements and constraints.
- Using Machine Learning to Predict Value of Homes On Airbnb (opens in a new tab)
- Using Machine Learning to Improve Streaming Quality at Netflix (opens in a new tab)
- 150 Successful Machine Learning Models: 6 Lessons Learned at Booking.com (opens in a new tab)
- How we grew from 0 to 4 million women on our fashion app, with a vertical machine learning approach (opens in a new tab)
- Machine Learning-Powered Search Ranking of Airbnb Experiences (opens in a new tab)
- From shallow to deep learning in fraud (opens in a new tab)
- Space, Time and Groceries (opens in a new tab)
- Creating a Modern OCR Pipeline Using Computer Vision and Deep Learning (opens in a new tab)
- Scaling Machine Learning at Uber with Michelangelo (opens in a new tab)
- Spotify's Discover Weekly: How machine learning finds your new music (opens in a new tab)