In this post, we will discuss the goals of designing an ML system. We will also get an idea about different types of ML systems.
Goals of ML systems design
ML system design is the process of defining the interface, algorithms, data, infrastructure, and hardware for an ML system to satisfy specified requirements.
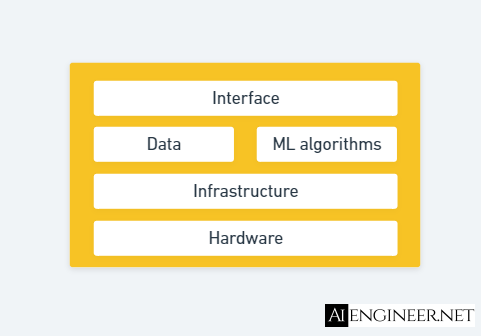
There're four main characteristics that an ML system should have, including:
- Reliability
- Scalability
- Maintainability
- Adaptability
Reliablity
The system should continue to perform the correct function at the desired level of performance even in adversity (hardware or software faults, and even human error).
For example, what if your predict() function is called correctly, but the prediction is wrong? How do we know if it is wrong if we don't have the ground truth labels to compare? You probably want to think about a way to handle this case in your system.
Scalablity
As the system grows in data, traffic, etc., there should be reasonable ways to expand and reduce resources when needed.
Maintanability
ML engineers, DevOps/MLOps engineers, and Subject Matter Experts (SMEs) should be able to work productively together.
Besides the data labeling phase, you'd want SMEs to be involved in steps such as:
- Problem forming
- Feature engineering
- Error analysis
- Model evaluation
- Reranking predictions
- UI design
There're some known problems when collaborating among cross-functional teams. For instance, how do you explain an ML algorithm's limitations and capabilities to SMEs who might not have engineering or statistical backgrounds? How do you version SMEs' domain expertise (e.g., if the user's shoulder is tilted a little bit like this and that while his back is tilted a little bit like that and this, then it might be a sign of back pain).
Many companies developed node-code/low-code platforms that allow people to make changes without writing code.
Adaptability
To adapt to the change in data distribution and business requirements, the system should be able to both discover aspects for performance improvement and allow updates without service interruption.
For example, an ML system should have the functionalities such as:
- Data drift detection
- Auto model retraining triggering
- Auto A/B testing between model versions
- Auto shifting data and allowing rollback in model deployment
Types of ML Systems

We can categorize ML systems based on three aspects:
- Prediction serving types: Batch prediction vs. Online prediction
- Computation technology: Edge computing vs. Cloud computing
- Learning strategy: Online learning vs. Offline learning
Batch prediction vs. Online prediction
Below is the table to compare these two types of ML systems.
| Batch prediction | Online prediction | |
|---|---|---|
| Frequency | Periodical | As soon as the request comes |
| Useful for | Processing accumulated data when we don't need immediate results | When predictions are required as soon as a data sample is generated |
| Optimized | High throughput | Low latency |
| Input space | Finite - Need to know how many predictions to generate | Can be infinite |
| Examples | Generate recommendations for users every few hours | Want to see a transaction is fraudulent as soon as possible |
They can be used in one hybrid solution, not necessarily be mutually exclusive.
When the online prediction is not cheap enough or is not fast enough, batch prediction is a workaround solution.
When you make a batch prediction, you need to consider the solution for storing and retrieving the pre-generated predictions.
Edge computing vs. Cloud computing
For edge computing, end devices should have enough memory and battery to store models and to make the inference.
The benefits of edge computing include:
- Might be able to work without an internet connection or with unreliable internet
- No need to worry about network latency
- Fewer concerns about privacy
- Save on server cost
For cloud computing, the network connections should be fast and reliable.
Online learning vs. Offline learning
Below is the summary table to compare these two types of ML systems.
| Online learning | Offline learning | |
|---|---|---|
| Interaction cycle | Continual (minutes) | Periodical (months) |
| Batch size | Hundreds | Thousands to millions |
| Data usage | Each sample seen at most once | Each sample seen multiple times (epochs) |
| Evaluation | Offline evaluation as the sanity check. Mostly relying on online evaluation (A/B Testing) | Mostly offline evaluation |
If the infrastructure is set up correctly, there's no difference between online and offline learning. We just need to tune the batch size or how often to evaluate models.
Companies also train their models offline in parallel and then combine offline with online versions.
Ending
Let's keep this post not too long. In the next post, we will see the iterative process of an ML system, especially the questions you need to discuss with your teammates to scope your ML system.