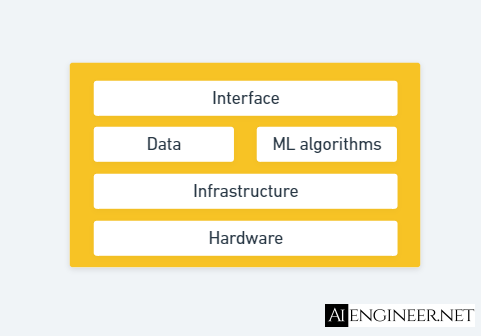
ML system design is the process of defining the interface, algorithms, data, infrastructure, and hardware for an ML system to satisfy specified requirements. When it comes to ML infrastructure, you might have heard about many keywords like microservices, lambda functions, load balancers, auto-scaling, serverless, etc. Indeed, ML infrastructure is complex. This post gives you a high-level overview of ML infrastructure and which components aggregate it.
In general, infrastructure is the set of basic facilities and systems that support the sustainable functionality of households and firms. ML infrastructure is the set of basic facilities that support the development and maintenance of ML systems. Every company's infrastructure needs are different. For example, a simple ML app doesn't even need a dedicated ML infrastructure, the vast majority of apps at a reasonable scale just need a simple ML infrastructure, some apps from big tech companies need highly specialized infrastructure which supports millions of requests per hour.
The ML infrastructure has four primary layers, including the storage and computes layer, resource management layer, ML platform layer, and development environment layer.
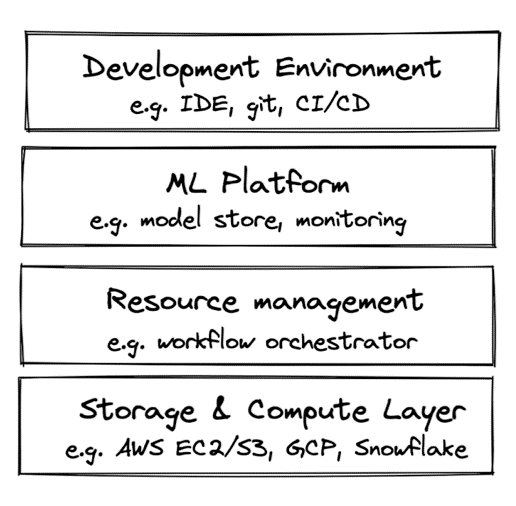
Storage and compute
Storage is where data is collected and stored. Some examples are HDD, SSD, data lake, and data warehouse. Some services and platforms are very famous such as AWS S3, Redshift, Snowflake, BigQuery, etc. Most companies use storage provided by other companies (e.g., cloud). Storage has become so cheap that most companies just store everything.
Compute is the engine to execute our jobs. In short, they are CPU, GPU, memory, and cloud computing. When talking about computing, there are some aspects we should consider.
- The number of CPU/GPU cores
- Amount of memory
- I/O bandwidth: the speed at which data can be loaded into memory. For example, floating-point operations per second (FLOPS).
- Cost: on-premises, cloud, or multi-cloud
Resource management
ML workloads are repetitive with many dependencies such as batch prediction, periodical retraining, periodical analytics, etc.
Scheduler and Orchestrator
In the resource management context, we want to use Scheduler or Orchestrator. Schedulers are cron programs that can handle dependencies. Most schedulers require to specify the workloads as Directed Acyclic Graphs (DAGs). The scheduler can handle event-based and time-based triggers. If a job fails, we need to determine how many times to retry before giving up. Jobs can be queued, prioritized, and allocated resources. Schedulers are aware of the resources available and resources needed for each job. There are some known challenges to designing a scheduler, such as:
- General-purpose schedulers are extremely hard to design
- Need to handle any workload with any number of concurrent machines
- If the scheduler is down, every workflow that the scheduler touches will also be down
Scheduler helps to define when to run jobs. It handles jobs, queues, user-level quotas, etc. The scheduler is typically used for periodical jobs like batch jobs.
Orchestrator helps to define where to run jobs. It handles containers, instances, clusters, replication, etc. It also helps to allocate more instances to the instance pool as needed. Orchestrator is typically used for long-running jobs like services.
Schedulers usually have some orchestrating capacity and vice versa. Often, a scheduler is run on top of orchestrators. For example, running Spark's job on top of k8s and running AWS Batch scheduler on top of EKS.
ML workflow management
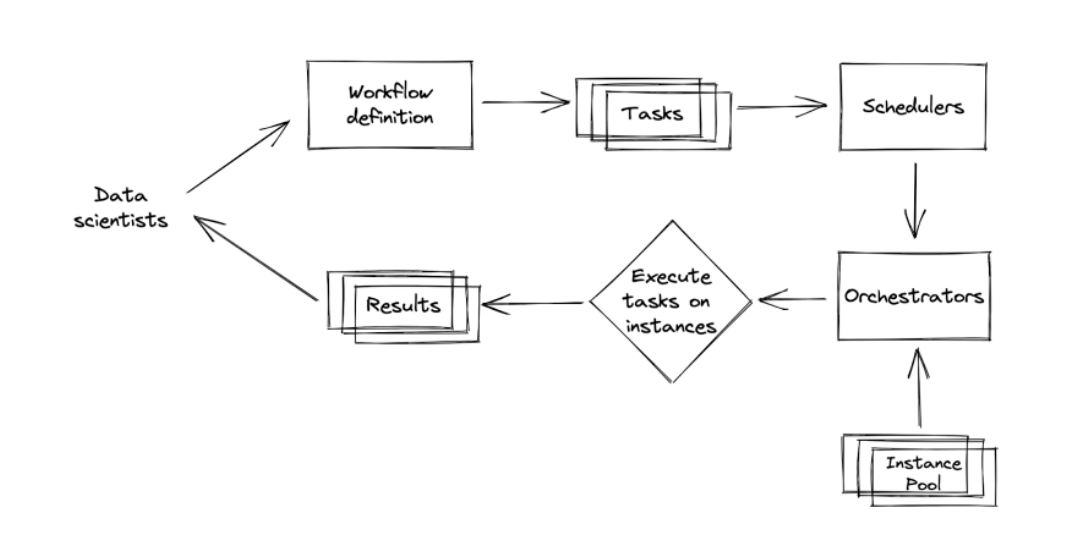
The ML workflow can be defined by using a programming language (Python) or configuration files (YAML). Some tool examples are Airflow, Argo, KubeFlow, and Metaflow.
ML platform
To deploy an image classification model, X's team needs to build tools like feature store, model store, model deployment, etc. Y's team needs to create the same tools to deploy an object detection model. The company decided to build a centralized platform to provide the above tools for multiple use cases. This centralized platform is the ML platform.
ML platform consists of three key components.
- Model deployment
- Deployment service
- Package the model and dependencies
- Push the package to production
- Expose an endpoint for prediction
- Common MLOps tool
- Cloud providers: SageMaker (AWS), Vertex AI (GCP), AzureML (Azure), etc.
- Independent: MLflow Models, Seldon, Cortex, Ray Serve, etc.
- Challenges
- How to ensure a model's quality pre and during deployment?
- Deployment service
- Model store must ensure when something happens, how to figure out:
- Who is responsible for a model?
- If the correct model binary was deployed?
- If the used features are correct?
- If the code is up-to-date?
- If something happened with the data pipeline?
- The feature store has some key challenges
- Feature management
- How to share features between multiple models
- How to allow different teams to find and use features discovered by other teams?
- Solution: use the feature catalog
- Feature consistency
- Features might be written in Python during training and in Java during deployment
- How to ensure consistency between different feature pipelines?
- Feature computation
- It might be expensive to compute the same feature multiple times for different models
- How to store computed features so that other models can use them?
- Solution: use the data warehouse
- Feature management
ML platform might consist of other components such as.
- Monitoring: for operational metrics and ML-specific metrics
- Experimentation platform
- Measurement: for business metrics
When working with MLOps tools, we need to evaluate them based on some questions.
- Does it work with our cloud provider?
- Is it an open-source or managed service?
- Does it satisfy data security requirements?
- etc.
Development environment
The development environment includes the following concerns.
- The IDE: vscode, vim
- Notebook: Jupyter notebooks, Colab
- Versioning tools: Git for code versioning, DVC for data versioning, WandB and MLflow for experiment versioning
- CI/CD test suite
- Standardization
- Standardize dependencies with versions
- Standardize tools and versions
- Standardize hardware: use a cloud development environment
- Simplify IT support
- Security: revoke access if the laptop is stolen
- Bring the development environment closer to the production environment
- Make the debugger easier
Ending
A typical ML Infrastructure has four layers, and the ML Platform is the third layer of it. ML Infrastructure is just a part of an ML System besides the hardware, data, ML algorithms, and the interface. This post helps you differentiate the ML System, ML Infrastructure, and ML Platform in a simple way.