
Scaling relational databases
Relational databases are typically suitable for handling relatively small amounts of data. However, as data grows, there are various approaches to scaling them.
Scaling up
One approach to scaling relational databases is to deploy them on more robust hardware, but this has certain drawbacks.
| Drawback | Description |
|---|---|
| Cost | The expenses associated with hardware increase exponentially as more powerful hardware is required |
| Availability | Relying on a single machine creates a single point of failure |
| Migration | As data continues to grow, migrating to more powerful hardware becomes necessary |
| Distant serving | Serving services that are far from the server can lead to increased latency |
Scaling out: Read replicas
A common approach to scaling out is to utilize read replicas, where the main database node serves as the primary node and the read replicas act as secondary nodes. Writes are directed to the primary node, and changes are asynchronously replicated to the secondary nodes, which could be located in different geographical locations. This type of architecture is often referred to as read replication or primary/secondary-based database architectures.
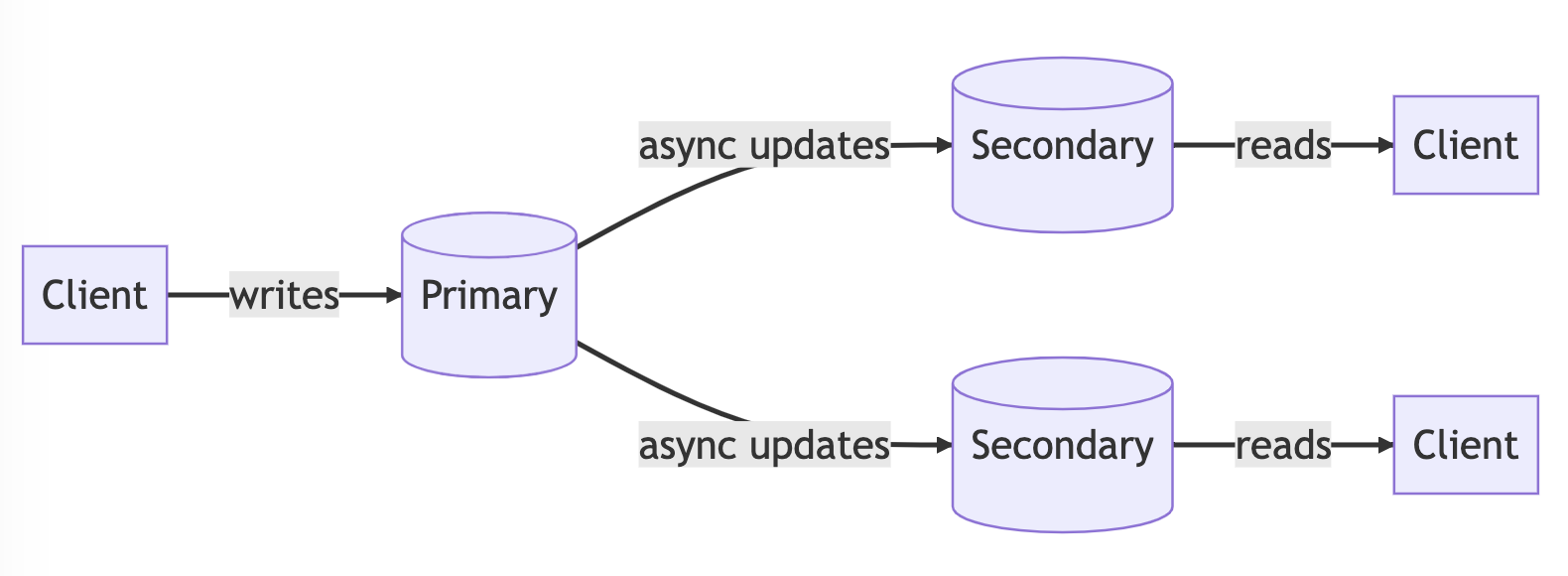
This approach is effective for applications with a high read load. However, there may be a slight delay of a few milliseconds between when data is written to the primary node and when it is replicated to the secondary nodes. As a result, clients may potentially read outdated data from the secondary nodes.
Scaling out: Partitioning data
Splitting or partitioning data is another approach for distributing a database across multiple independent disk partitions and database engines. There are two main strategies for this: horizontal partitioning and vertical partitioning.
| Strategy | Description | Example |
|---|---|---|
| Horizontal partitioning | Dividing rows into multiple partitions based on certain values | Hashing the primary key to split the data |
| Vertical partitioning | Dividing a table by columns | Storing read-only columns and others in separate tables |
A database engine can support partitioning tables on disk or across nodes to achieve horizontal scalability. However, this technique also has some challenges. For example, when a request needs to join data from multiple partitioned tables, it may require high-bandwidth network traffic and joining coordination, which could potentially impact performance.
Scaling non-relational databases - NoSQL
Non-relational databases, also known as NoSQL databases, are often characterized by their schemaless nature, which includes the following properties:
- Simplified data models that can be easily changed
- Limited or no support for joins in proprietary query languages
- Ability to horizontally scale on low-cost hardware
When designing relational databases, the focus is on modeling the problem domain, and SQL and joins are used to reference the data. However, when designing with NoSQL databases, the focus is on modeling the solution domain. This involves designing common data access patterns that the application supports. When reading data, the data must be pre-joined to serve requests, which can be thought of as creating a table for each use case instead of for each object. This trade-off between flexibility and efficiency is inherent in the solution domain modeling approach.
NoSQL data models
There are 4 main NoSQL data models.
| Data model | Description | Example |
|---|---|---|
| Key value (KV) | Represents a hash map where values can be strings, JSON, images, etc. | Redis, Oracle NoSQL |
| Document | Similar to KV model and relational tables, but without a requirement for uniform document format | MongoDB, Couchbase |
| Wide column | Represents a 2-dimensional hash map that allows sorting by columns, with flexibility in column usage | Apache Cassandra, Google Bigtable |
| Graph | Designed for highly connected data with relationships between database objects | Neo4j, Amazon Neptune |
Data distribution
NoSQL databases are specifically designed for horizontal scaling across distributed nodes, which eliminates single points of failure and improves performance, scalability, and availability (except for graph databases, which will not be discussed here).
Partitioning or sharding is a technique used to evenly distribute data objects across different nodes. Sharding involves using a shard or partition key that maps the object to a specific partition on a node.
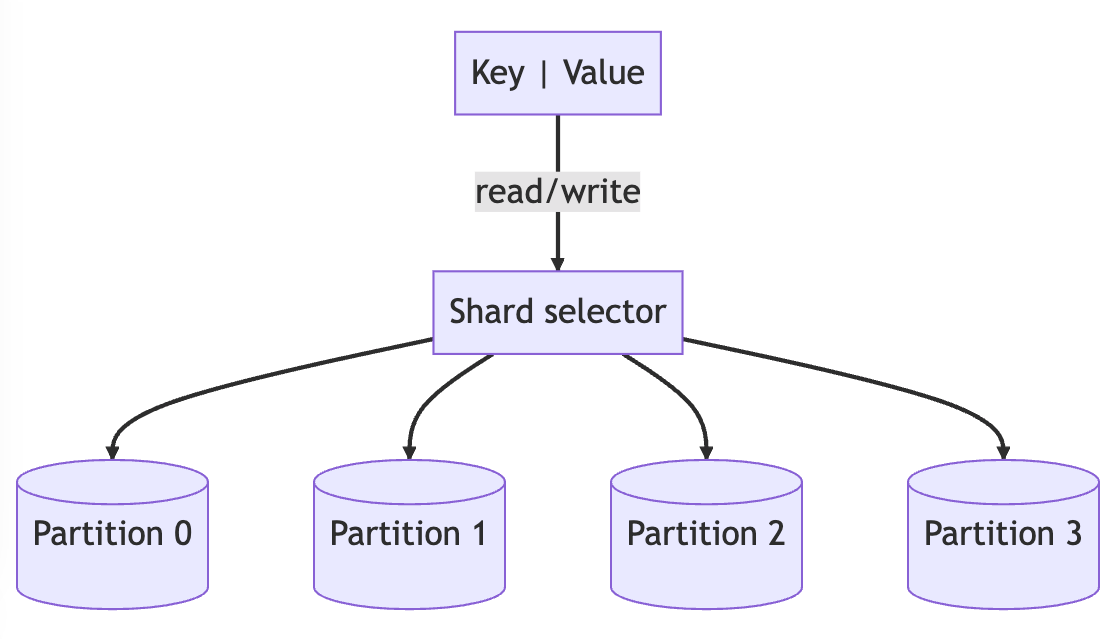
There are 3 main techniques for selecting the partition in sharding.
| Sharding technique | Description |
|---|---|
| Hash key | Apply a hash function to the shard key using modulus or consistent hashing |
| Value-based | Use the value of the shard key, such as country |
| Range-based | Define the partition based on the range of values of the shard key |
When data is distributed across nodes, if a partition becomes unavailable, the corresponding data chunk cannot be accessed. This can be addressed by replicating data in each partition to multiple replicas hosted on different nodes, typically more than 2 replicas. However, update requests would require all replicas to be updated.
There are 2 fundamental architectures for managing replication in distributed databases.
| Architecture | Description |
|---|---|
| Leader-follower | In this architecture, the leader replica handles write operations, while the followers are read-only replicas. It is suitable for read-heavy applications |
| Leaderless | In this architecture, any replica can handle both write and read operations. Requested replicas must coordinate updates on other replicas. It is suitable for write-heavy applications |
The solution for replica consistency in distributed systems presents challenges. For instance, determining when and how updates should be sent between replicas to ensure data consistency. If all replicas always have the same value, it results in strong consistency, where clients must wait until all replicas are updated before an update is considered successful. On the other hand, if clients allow for a delay in data updates, the database can provide eventual consistency.
The CAP theorem
The CAP theorem dictates that a distributed data store can only deliver 2 out of 3 guarantees.
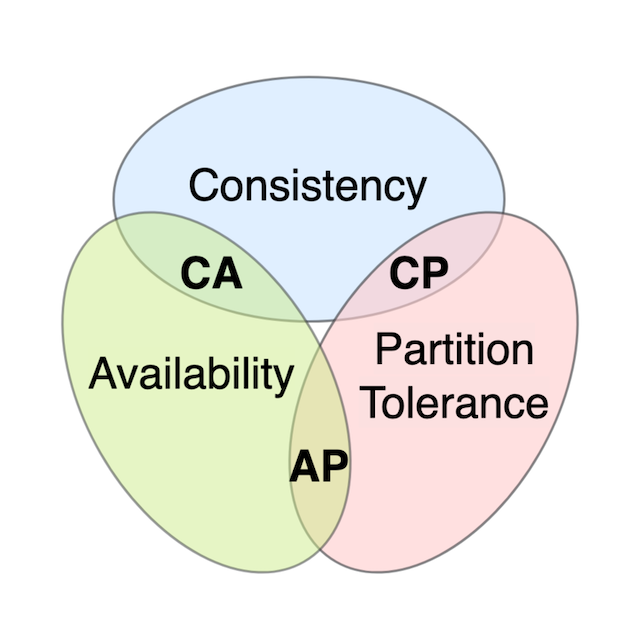 Source: Wikipedia (opens in a new tab)
Source: Wikipedia (opens in a new tab)
| Guarantee | Description |
|---|---|
| Consistency | Every read obtains either the most recent write or an error |
| Availability | Every request receives a response without errors, but without the guarantee of containing the most recent write |
| Parition tolerance | The system remains operational despite arbitrary messages being dropped/delayed by the network between nodes |
For instance, when an update occurs and the network between replicas fails, the database can either
- Return an error to maintain replica consistency (CP), which results in unavailability
- Or apply the update to the reachable subset of replicas (AP), allowing for inconsistency
You can read more about CAP theorem here (opens in a new tab).
Keynotes
- Scaling up: involves increasing the resources of a single database instance to improve its performance
- Scaling out using read replicas: involves creating multiple copies of the database and distributing read requests across them to improve query response times
- Scaling out using partitioning data: involves dividing the database into smaller partitions that can be distributed across multiple servers to improve write performance and increase storage capacity
- NoSQL data models: are designed for horizontal scaling and can be more efficient than traditional relational databases
- CAP theorem: states that a distributed system can only guarantee two out of three properties: consistency, availability, and partition tolerance