
Service design
Suppose our application comprises a service and a database for storing information. Customers utilize the service's API to submit requests.
API
Although APIs can be created using the Remote Procedure Call (RPC) model such as gRPC, the prevalent style is HTTP APIs, which are commonly known as RESTful APIs. The CRUD HTTP API pattern explains how clients perform operations like create, read, update, and delete in a business context, with each operation corresponding to an HTTP method, namely POST, GET, PUT, and DELETE, respectively.
| POST | GET | PUT | DELETE | |
|---|---|---|---|---|
| Purpose | Create an object | Read object(s) | Update an object | Delete an object |
| URI example | /cars | /cars/car-id | /cars/car-id | /cars/car-id |
| Request example (JSON) | { "name": "car-name" } | No payload | { "name": "new-name" } | No payload |
| Response example (JSON) | { "id": "car-id", "name": "car-name" } | { "id": "car-id", "name": "car-name" } | Empty | Empty |
| Response code example | 201 | 200 | 200 | 200 |
To exchange information, requests, and responses typically use JSON or XML formats. Resource identification, modeling, and resources (such as cars) follow an object-oriented design in URIs. OpenAPI (opens in a new tab) is an open-source format used to document APIs. Swagger (opens in a new tab), which uses YAML to adhere to the OpenAPI format, can be used to define APIs.
API design is a complex subject with best practices available online. From the scalability perspective, we should consider the following issues:
- When a client makes an API request, it introduces network latency since it involves a round trip to the service
- If the payloads are large, it's advisable to use compression techniques such as
gzipwithAccept-EncodingandContent-Encodingheaders to minimize network bandwidth and latency. However, this approach requires additional time and resources to compress and decompress content on both ends. This overhead is generally insignificant compared to the time taken for network transmission.
State management
When clients send requests to a server to retrieve or update information, the server may retain certain information, known as conversational state, between requests. This allows subsequent requests to assume that the server has retained that information. Services that maintain conversational states are known as stateful services. However, in terms of scalability, it is generally preferable for services to be stateless and avoid storing conversational states. This is because storing conversational states can use up more memory as the number of clients increases, and the timeout period of the session state is to be considered.
Stateless services, on the other hand, assume that each request includes enough client information to proceed independently of prior client activities. Any conversational state that is required should be stored in an external data store.
Any scalable service will need stateless APIs.
Application servers
Handlers are defined within the application service code to handle requests and execute business logic that generates results for the requests.
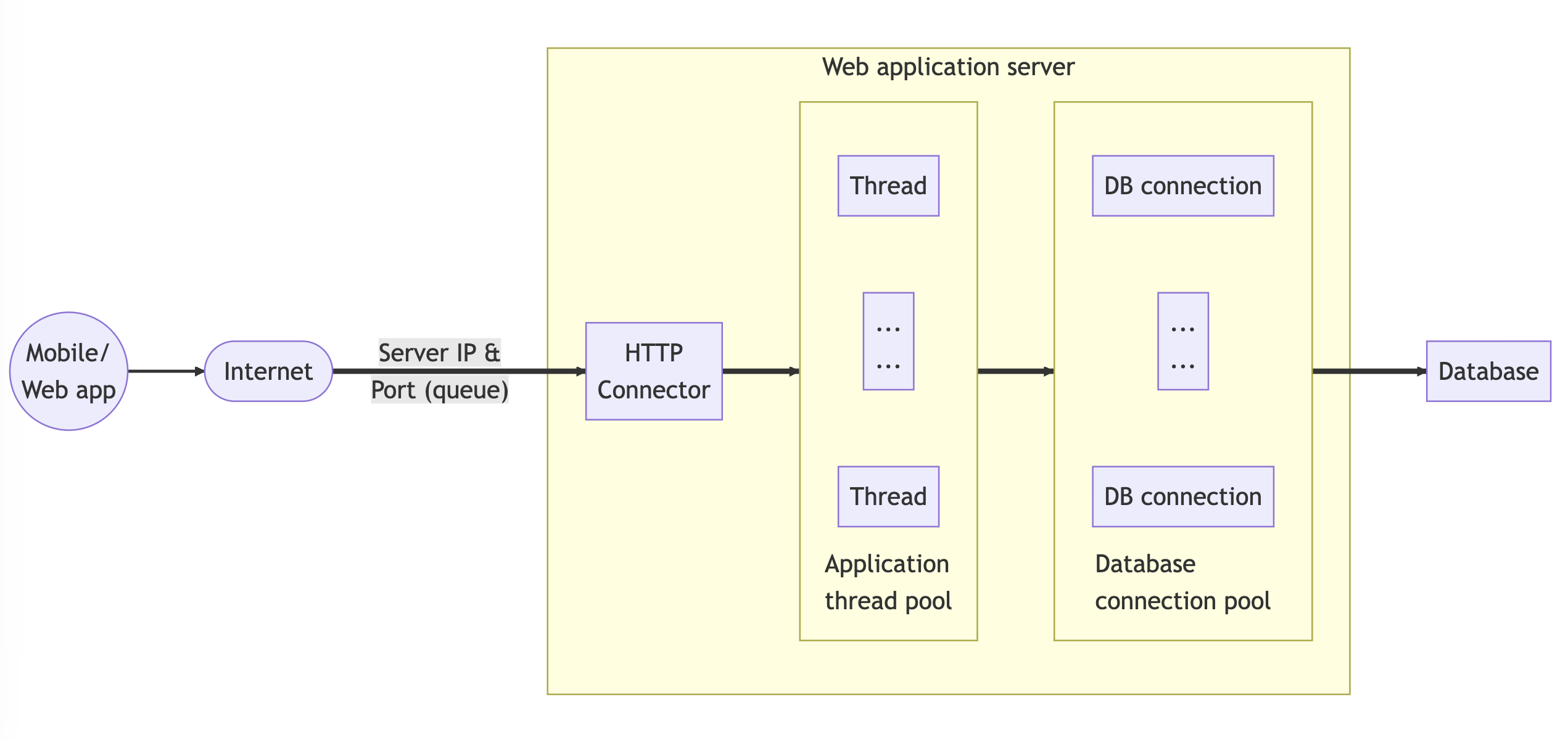
Routing requests based on their HTTP method and API signature is a common practice in application development. Different technology platforms and programming languages provide various mechanisms for request routing. For instance, in Go programming language, we can use the gin framework (opens in a new tab), as shown below:
package main
import (
"net/http"
"github.com/gin-gonic/gin"
)
func main() {
r := gin.Default()
// Define the handler function for the '/ping' route with GET method
r.GET("/ping", func(c *gin.Context) {
c.JSON(http.StatusOK, gin.H{
"message": "pong",
})
})
r.Run() // listen and serve on 0.0.0.0:8080
}When a new request arrives, it is processed by acquiring a new thread from the thread pool. The handler function responsible for executing the business logic processing may require accessing or updating data in the database. In such a case, the process will obtain a database connection and execute the necessary queries. However, the application server's ability to maintain threads and the database engine's ability to maintain connections are limited due to their consumption of system resources and memory.
To avoid the overhead of creating new threads or database connections for each request, a thread pool and database connection pool are used. Since creating a thread or database connection is time-consuming, the thread pool is usually larger than the database connection pool. As a result, the database connection pool must maintain a queue to serve the requesting threads as needed. When designing these pools, several factors should be considered, including:
- The maximum number of threads/connections
- The maximum number of idle threads/connections
- The maximum lifetime of a thread/connection
- The maximum idle time of a thread/connection
When the number of allocated threads is too high, it can lead to slow context switching and limited memory availability. If the queue size is exceeded by the number of incoming requests, new connections will be declined and result in errors for clients. Ultimately, the server can exhaust its resources and crash.
Waiting until the server reaches maximum utilization can be too late. It's essential to have a utilization target or threshold for key metrics such as latency, request volume, queue sizes, etc. to enable horizontal scaling.
Horizontal scaling
In many situations, a straightforward and efficient method to scale your system is to deploy multiple instances of stateless servers and use a load balancer to distribute the traffic across these instances. With stateless servers, requests can be sent to any server replica, which enables horizontal scaling.
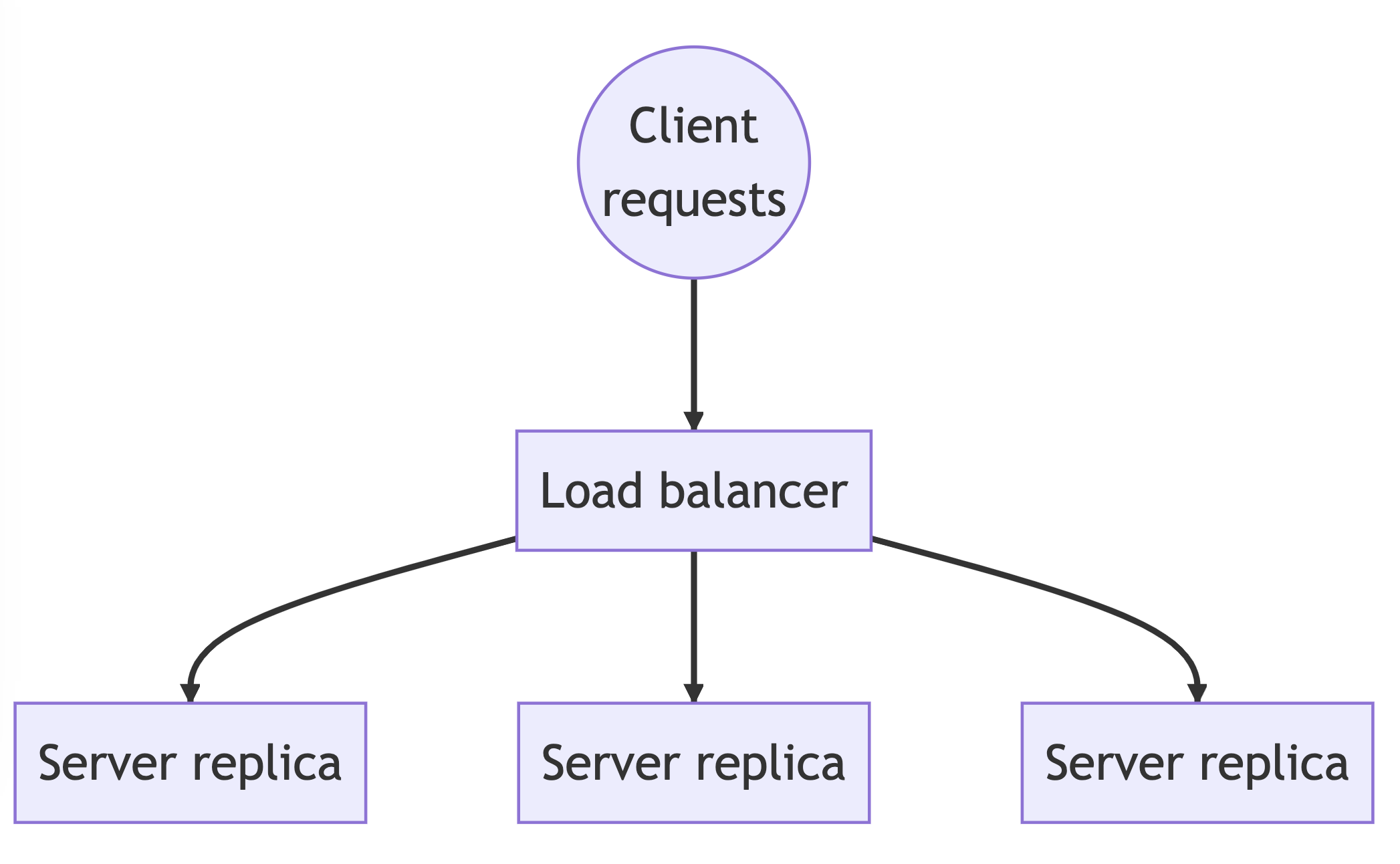
To achieve horizontal scaling, requests are first sent to the load balancer, which then distributes the requests among the server replicas. Having multiple replicas enhances availability and prevents a single point of failure. However, expanding the capacity of a service could potentially overwhelm the downstream services.
Load balancing
Load balancers are server instances or services that help distribute incoming requests across server replicas to optimize response time and take advantage of replicas' capacity. They also enhance the security of the system by not allowing clients to send requests directly to servers. Load balancers are commonly implemented at the network and application layers, which correspond to layers 4 and 7, respectively, in the Open Systems Interconnection (OSI) model (opens in a new tab).
Layer-4 or network load balancers distribute requests based on individual TCP/UDP packets, and routing decisions are made according to the client's IP addresses. These load balancers use Network Address Translation (NAT) (opens in a new tab) to modify the destination IP address of the request from the load balancer's IP address to the selected server replica's IP address. Similarly, when the server responds, NAT changes the source IP address from the server's IP address to the client's IP address.
Layer-7 or application load balancers, on the other hand, make routing decisions by examining the HTTP request's header. They can provide various features, such as load distribution strategies, health monitoring, auto-scaling, sticky sessions, and authentication, among others.
Load distribution strategies
Load distribution strategies are used by load balancers to determine which server replica to select for each request. There are several commonly used strategies, including:
- Least connections: Select the replica that currently has the fewest open connections
- Round robin (opens in a new tab): Select replicas in a sequential order, cycling through the available replicas
- HTTP header or method: Select replicas based on information in the HTTP header or method
- Replica weights: Select replicas based on their weights, which can be determined by factors like the number of vCPUs or available memory. Replicas with higher weights are selected more frequently
Health monitoring
Health monitoring is a feature provided by load balancers that involves periodically pinging replicas to verify their availability. These tests referred to as health checks, enable the load balancer to exclude any unavailable replicas from the load balancing pool or add them back to the pool once they are deemed healthy.
Autoscaling
The ability to provision new replicas dynamically to handle traffic increases is called autoscaling. To enable this feature, you need:
- A monitoring application to track the utilization of replica resources
- Integration between the load balancer and the monitoring application to determine when to scale up or down
- A scaling policy to specify how to scale up or down, such as adding one more replica if the average CPU usage across all instances exceeds 80% for three minutes
Sticky sessions

Load balancers that support sticky sessions enable requests from the same client to be directed to the same service replica. This allows your system to support stateful services that maintain conversational states about each specific client session. However, sticky sessions can lead to issues such as load imbalance. For instance:
- Clients may be connected to one replica while other replicas remain idle
- Some sessions may be terminated faster than others, leading to the overloading of some replicas and underutilization of others
- In the event of a replica failure, how do the connected clients recover the managed session?
Load balancing consideration
Introducing a single load balancer creates a potential single point of failure. If the load balancer loses power, internet connectivity, or crashes, it can lead to the loss of connections to your service replicas. To mitigate this risk, adding a standby load balancer that can take over if the primary one fails is recommended.
However, keep in mind that adding a load balancer introduces an additional network hop, which can result in time overhead for each request.
Keynotes
- Service design should focus on scalability from the beginning to support growth in traffic and user base
- Designing stateless APIs can help with scaling horizontally and distributing traffic to multiple application servers
- Load balancers can help distribute traffic across multiple server instances, improving response time and avoiding single points of failure
- Health monitoring can help ensure the availability of server instances by testing their availability and removing them from the pool if they are unavailable
- Auto scaling can dynamically provision new server instances to handle increased traffic load based on resource utilization metrics
- Sticky sessions can help maintain conversational states for stateful services but can also lead to load imbalances and other issues