
Main concepts
In distributed systems, databases need to handle challenges such as network latencies and machine failures, which can result in inconsistencies among replicas.
Inconsistency window
The inconsistency window refers to the time it takes for an update to be propagated to all replicas. Several factors can affect the duration of the inconsistency window.
| Factor | Description |
|---|---|
| Number of replicas | The more replicas there are, the longer it may take to update data |
| Operational environment | Factors such as network failures, packet loss, or heavy read/write workload can affect the inconsistency window |
| Distance between replicas | Replicas located in different continents may have a larger inconsistency window |
Read your own writes
Read your own writes (RYOWs) ensures that when a client updates data (client A), subsequent reads from the same client (client A) will return the updated data value.
The following scenario explains the issue when a client is unable to read their own writes.
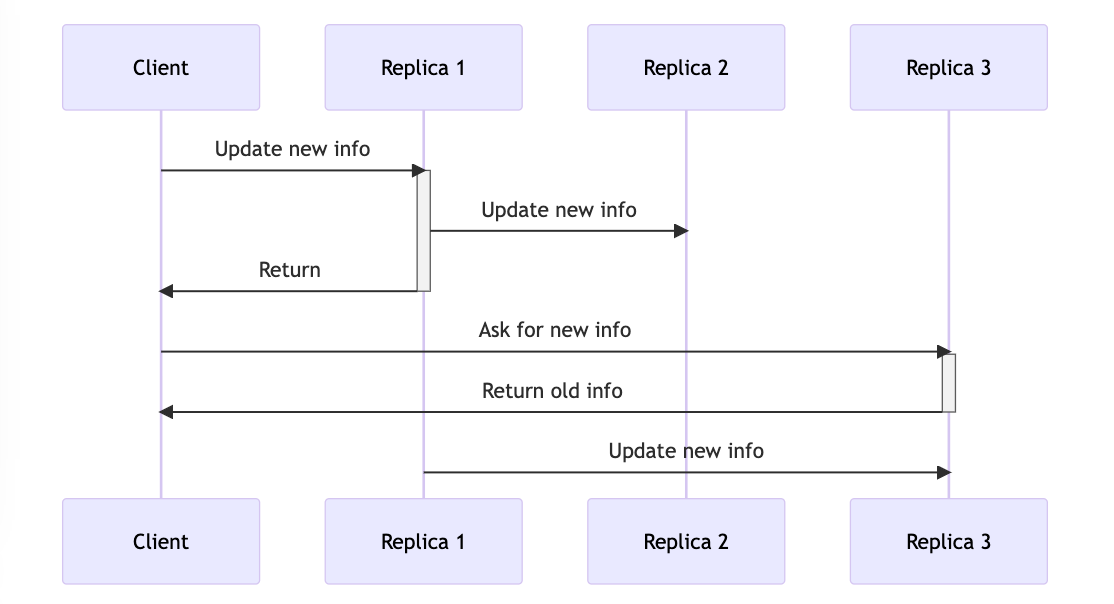
Replica 1 manages the client request to update information and sends the new information asynchronously to the other replicas. But there is a delay in updating Replica 3. In the meantime, the same client makes a read request, which goes to Replica 3, resulting in a stale read.
Tunable consistency
Adjustable consistency involves a trade-off between performance (e.g., latencies) and the inconsistency window. It depends on the following factors:
- N: Total number of replicas
- W: Number of replicas that need to finish updating before confirming the update
- R: Number of replicas to read from before returning a value
From a consistency standpoint, here are some examples:
- N=3, W=3: All replicas are consistent. Writes may fail if a replica is not accessible, which affects availability. This prioritizes Consistency-Partition Tolerance (CP) in the CAP theorem
- N=3, W=1: The inconsistency window occurs in 1 replica. If R=1, the result may be stale. This prioritizes availability over replica consistency or Availability-Partition Tolerance (AP)
- R=N: An algorithm is used to determine which replica has the latest updated value
From the perspective of reads versus writes, here are two examples:
- W=N, R=1: This prioritizes both consistency and read latencies, resulting in slow writes
-
- W=1, R=N: This prioritizes both availability and write latencies, resulting in slow reads W=1, R=1: This allows for inconsistency but results in fast reads and writes
Quorum reads and writes
Quorum refers to the majority, which is (N / 2) + 1. With N=3, a quorum means a write must be successful at 2 replicas, and a read must access 2 replicas. By reading and writing from the majority of replicas, read requests will see the latest version of an object. The following diagram shows how quorums work with 3 replicas.
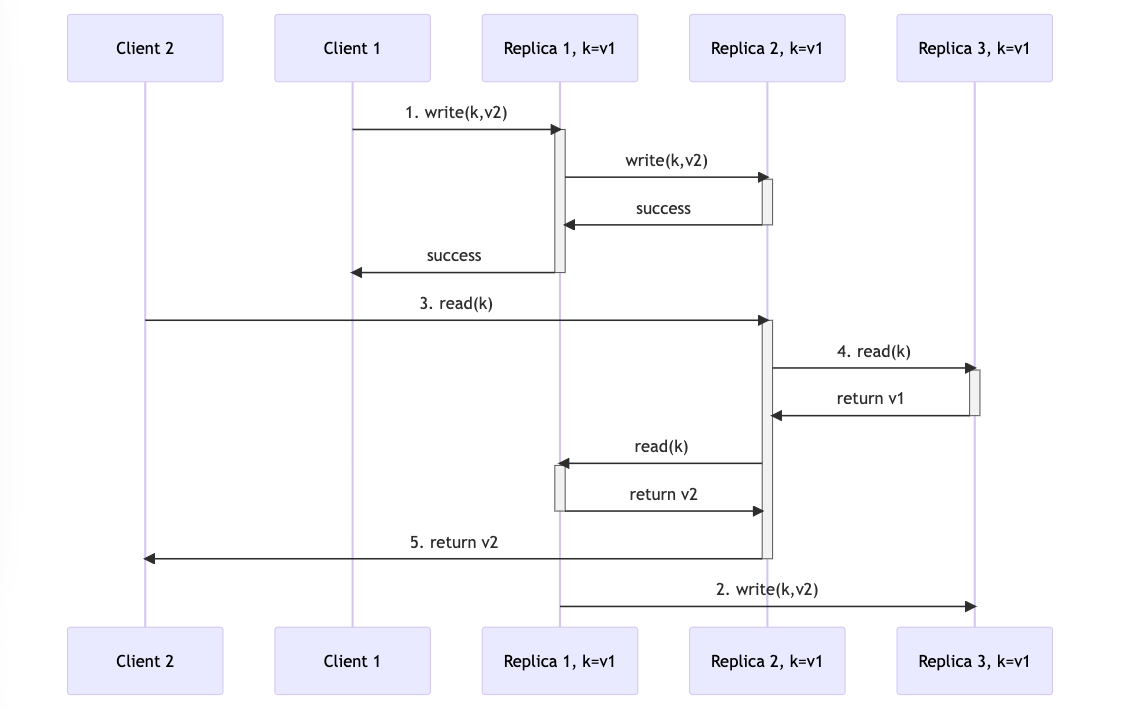
- The object is updated by Client 1 with value v2 and the write is confirmed only after a quorum (replica 1 and replica 2) is updated
- However, the update command to Replica 3 experiences a delay, possibly due to slow network
- Client 2 performs a read on object k
- Replica 2 serves as the request coordinator and sends a read request to the other two replicas for their values for k. Replica 3 responds first with k=v1
- Replica 2 compares its value for k with that returned from Replica 1 and Replica 3 and determines that v2 is the most recently updated value. It then returns the value v2 to Client 2
However, in case of a network failure that splits a group of replicas such that the group visible to a client does not contain a quorum, the client's requests may fail.
Sloppy quorum is introduced to overcome this issue by prioritizing availability over consistency. If a write cannot achieve quorum due to an unavailable replica A, the update can be temporarily stored on another reachable replica B. When replica A becomes available, replica B sends the update to A. This process is called a hinted handoff.
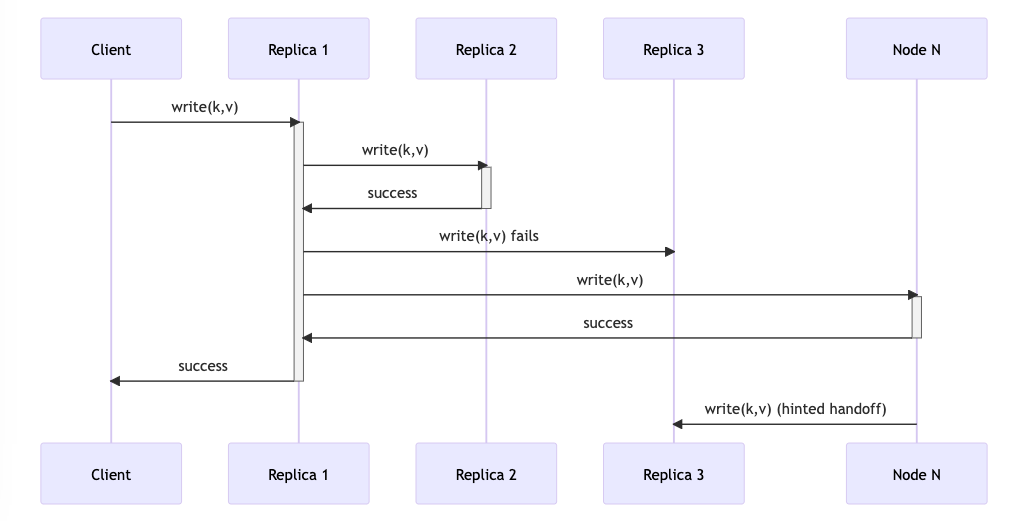
The client initiates an update request to Replica 1, which tries to replicate the update to Replica 2 and Replica 3. However, Replica 3 is not accessible due to a temporary network partition. So, Replica 1 forwards the update to another node, Node N, which holds it temporarily. After some time, Node N sends the update to Replica 3, ensuring that the value for the updated object is consistent across all replicas.
Sloppy quorums imply 2 things:
- A write can be updated on W nodes, but those W nodes might not hold the latest values due to the unavailability of some nodes. This means a read might still read a stale value
- It increases availability
Replica repair
Replica drift can make replicas inconsistent over time due to network failures, node crashes, etc. Databases typically use two strategies to repair and ensure replicas remain consistent: active repair and passive repair.
Active repair, also known as read repair, is triggered on read requests. When a read arrives at a coordinator node, it requests the latest value from each replica. If any values are inconsistent, the coordinator updates the latest value to the stale replicas in sync or async mode.
Passive repair runs periodically to fix replicas that are infrequently accessed.
Handling conflicts
When reading from 3 replicas in a database, determining the most recent update becomes crucial. In designs without a leader or coordinator, multiple replicas can handle writes concurrently, which can result in conflicts. Two main strategies to address this issue are the last writer wins and version vectors approaches.
Last writer wins
In the last writer wins strategy, the database uses timestamps to determine the latest update. However, this approach can result in data loss as updates may be silently discarded.
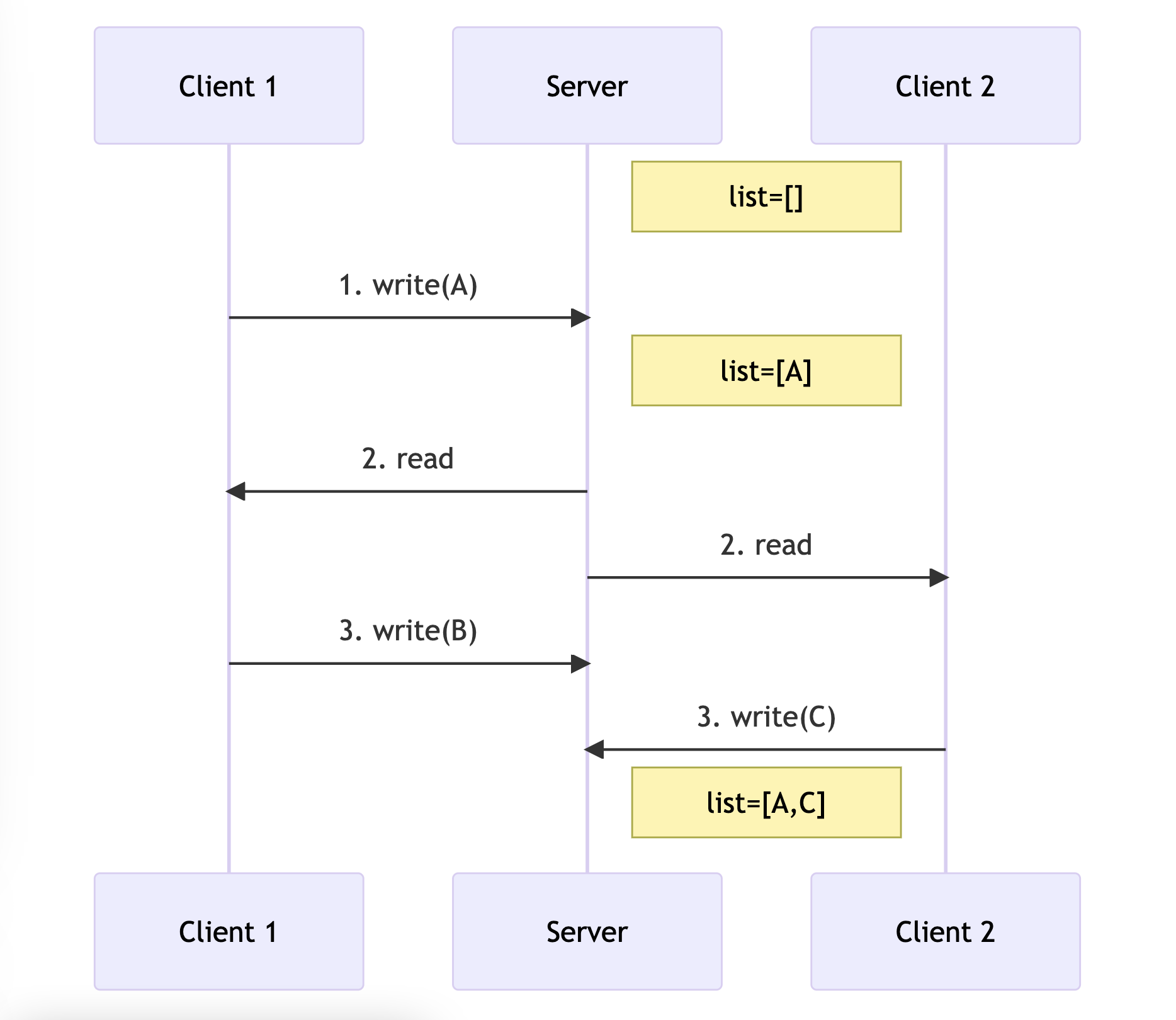
Client 1 adds item A to the list, which is later read by both Client 1 and Client 2. They both add a new item to the list, but since Client 2's update has a later timestamp than Client 1's, the changes made by Client 1 are discarded.
One solution is to use timestamps on individual fields and conditional writes. Alternatively, a better approach is to attach a write with a unique key, and make objects immutable, so that any changes to data require reading the existing object and writing new values with a new key.
Version vectors
In the version vectors strategy, each unique object in the database is associated with a version number. In a scenario with a single replica, the following steps are involved:
- When a client reads an object, both the object and its version number are returned
- When a client updates an object, it writes the new values along with the version number of the object that was received from the previous read
- The database checks if the received version number matches the current version number of the object. If it does, the write is accepted and the version number is incremented
- If the version numbers do not match, a conflict has occurred. The database may either return an error or perform value merging of some kind, and inform the client about the conflict
In the below figure, when there is a conflict in the database, it saves both versions of the object and notifies the client of the conflict. To resolve the conflict, the client needs to merge the two updates.
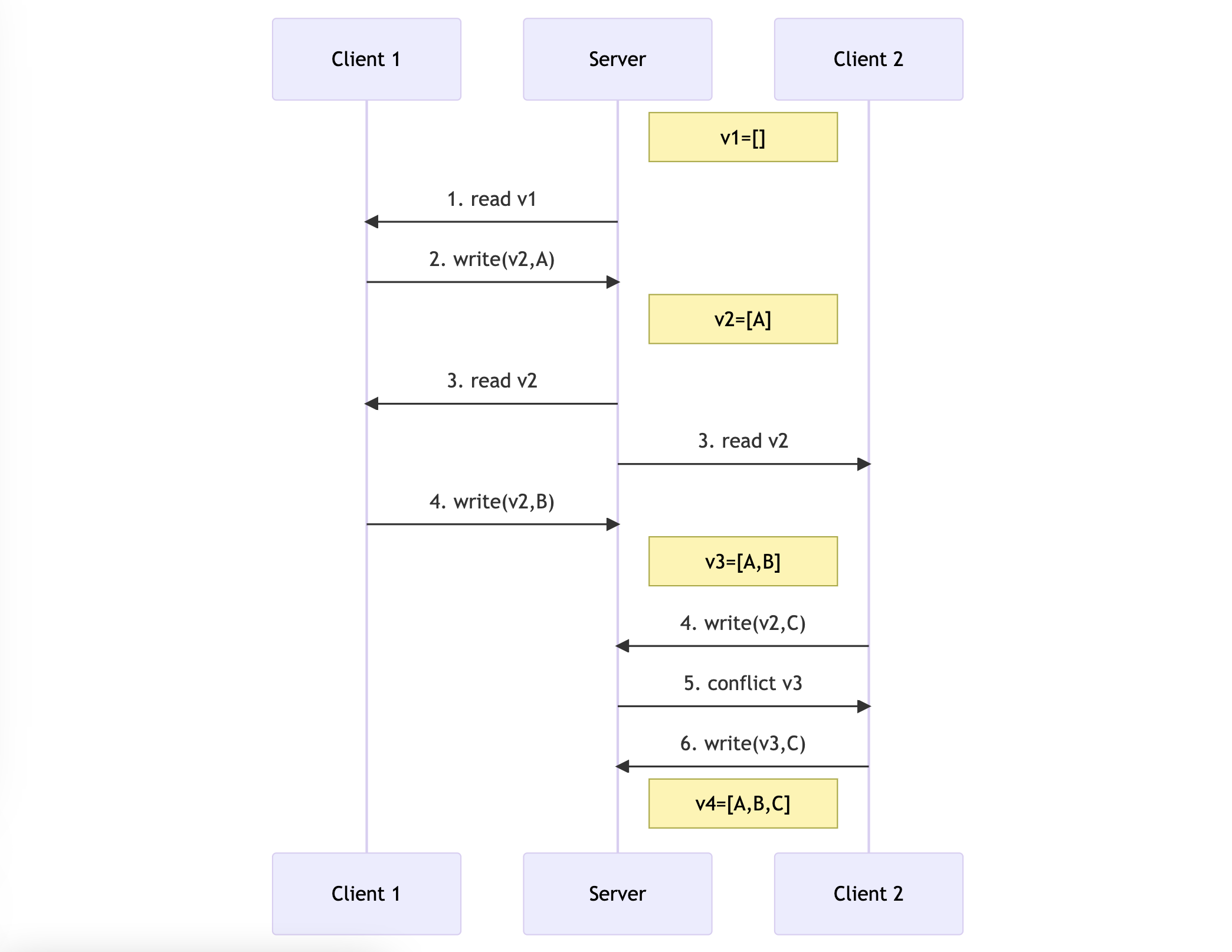
In a scenario with multiple replicas, each replica maintains its own version number as writes are processed and keeps track of the versions of other replicas it has seen. This creates a version vector.
When a replica accepts a write, it updates its own version number and sends the update request along with its version vector to other replicas. This version vector is then used by a replica to determine whether the update should be accepted or not.
Keynotes
- Inconsistency window refers to the time period during which a client may read stale data from a replica after making an update
- Read your own writes ensures that a client always sees the latest version of a data object it has written to
- Quorum reads and writes ensure that updates are only acknowledged when a majority of replicas have been updated
- Replica repair involves reconciling inconsistencies between replicas to ensure that all replicas have the same data
- Handling conflicts can be done using last writer wins or version vectors
- In last writer wins, the latest update overwrites previous ones
- In version vectors, each replica keeps track of the updates it has seen and resolves conflicts by comparing their version numbers