
Basic architecture
We begin with a basic distributed system architecture for an internet-facing system, consisting of a client tier, an application service tier, and a database tier. The diagram below illustrates this architecture.
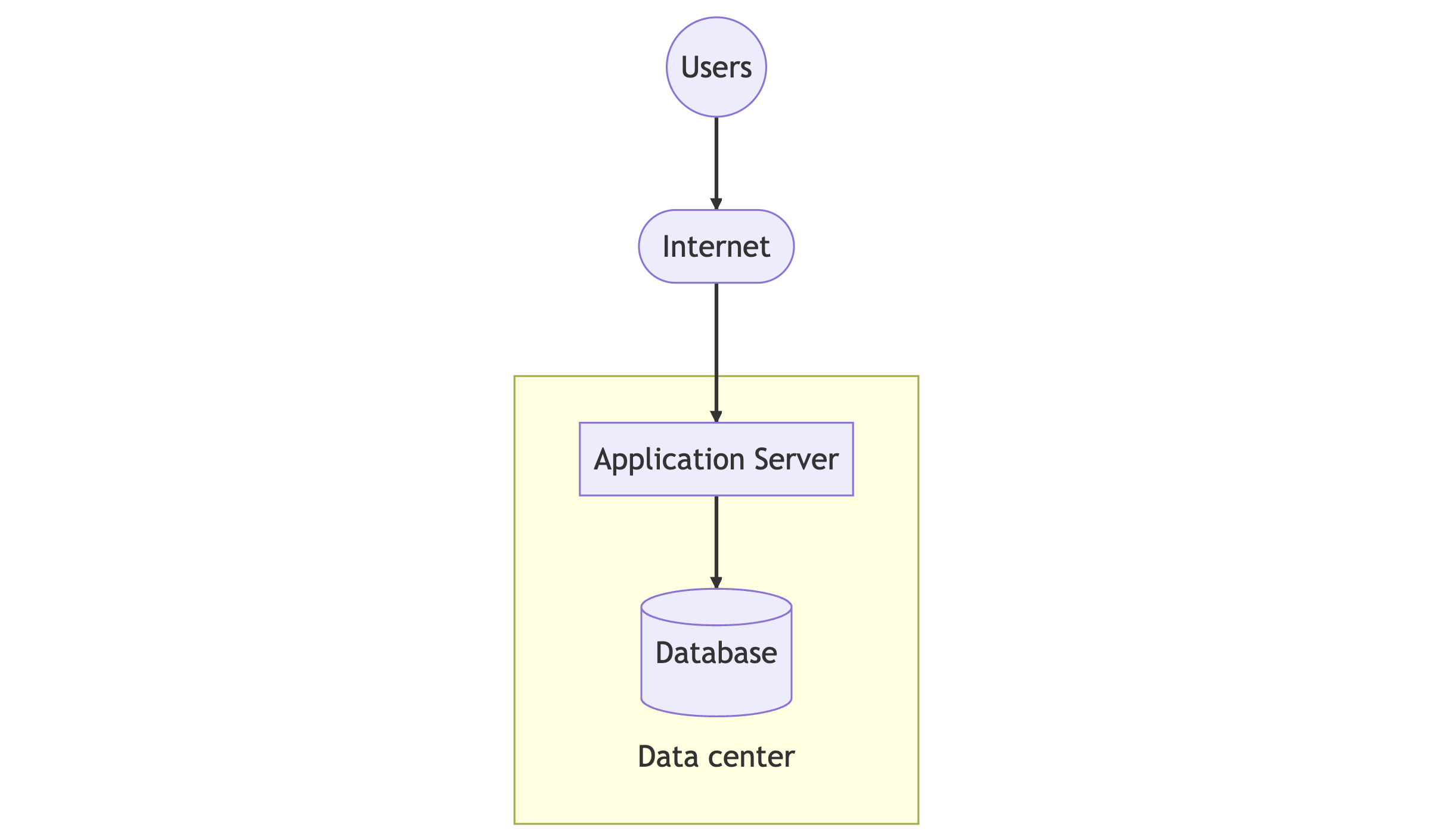
Initially, users send requests to the application from a mobile app or web browser. These requests are delivered over the internet to the application service, which is hosted in either an on-premise or commercial cloud data center. The standard application-level network protocol used is typically HTTP.
Upon receiving the request, the application service processes the requested API and may read from or write to a database. Once the processing is complete, the service sends the results to users for display on their mobile app or browser.
The above system can function well under low request loads. However, as the request loads increase, the system's single server will not have sufficient CPU/memory to handle concurrent requests, leading to longer response times.
To address this issue, one simple strategy is to scale up the application service hardware by upgrading to higher memory, such as 16Gi from 8Gi. However, in many applications, horizontal scaling, or scaling out, is necessary to handle increasing request loads as no matter how much CPU/memory is available, a single server node may not be sufficient.
Scaling out
To achieve horizontal scaling, a service can be replicated and run on multiple server nodes, with client requests distributed across the replicas. This approach requires two key elements: a load balancer and stateless services.
Load balancers
A load balancer is responsible for selecting a service replica to process each incoming request, to keep the replicas evenly loaded. Typically located between the client and the server, the load balancer needs to be extremely low latency to avoid introducing significant overhead.
Stateless services
For the scaling out approach to work effectively, stateless services are required. These services do not retain any session-specific state, allowing them to process requests from any client instance. Instead, the client state is typically stored elsewhere, such as in a database, or a session store.
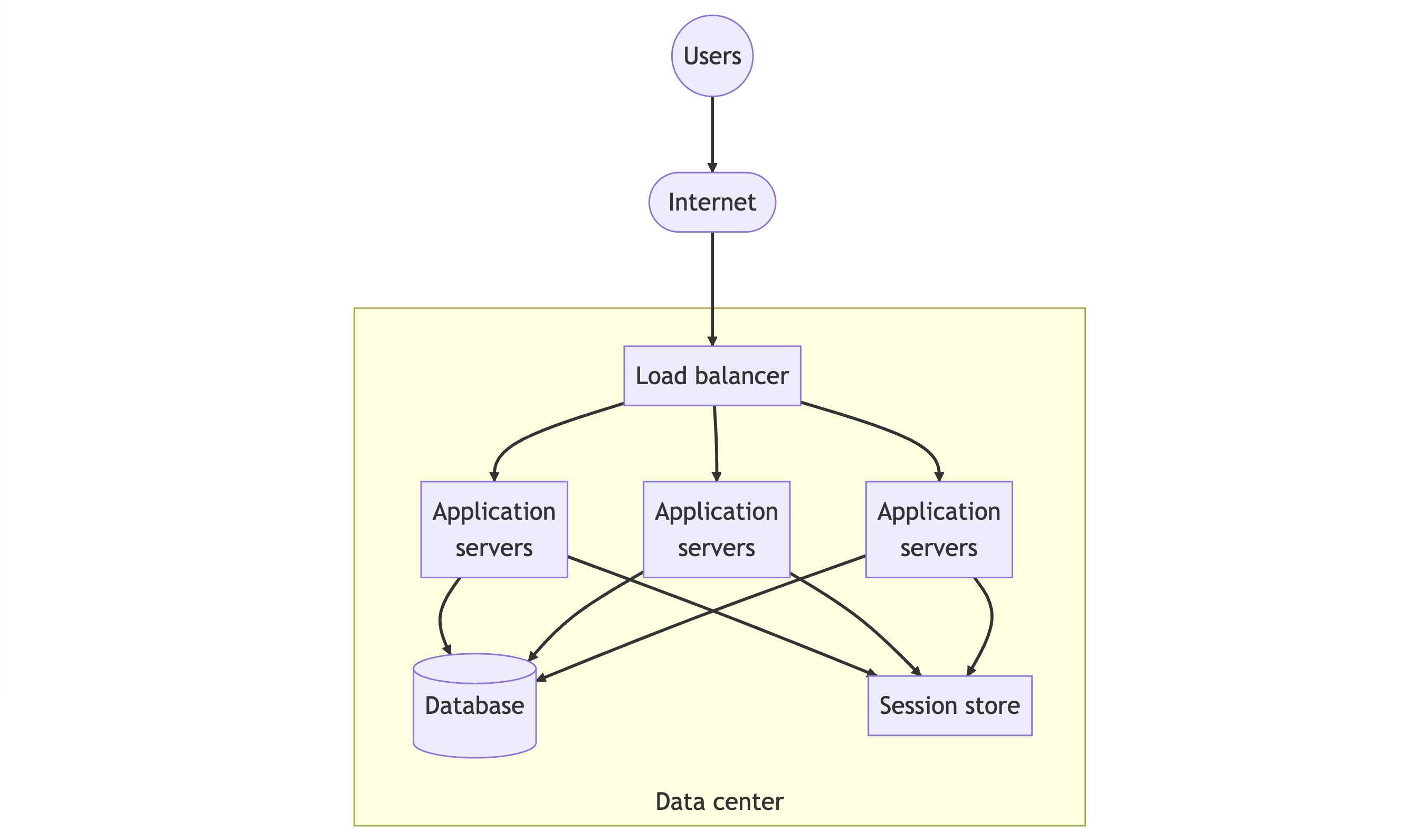
Scaling out with stateless services is a cost-effective way to increase system capacity without requiring code changes. When one instance fails, any requests it was processing are lost. But because the service is stateless, the state is stored elsewhere, so the requests can be easily recreated and sent to other instances. This makes the application resilient to failures, which improves the availability attribute.
However, adding more instances can cause an increased load on a single database. If requests grow faster than they can be processed, the database can become overloaded and become the bottleneck of the system.
Distributed cache
As data grows, storing it in large databases can impact the responsiveness of your application. To optimize the performance of your application, you can use various techniques such as query tuning, disk partitioning, indexing, and caching.
Database querying is often expensive and time-consuming. To reduce this overhead, you can implement distributed caching. This cache stores frequently accessed and recently retrieved database responses in memory. For instance, multiple AI services query the total number of orders in the last hour, which won't change frequently, or the list of items in the inventory. You can replace the session store with the distributed cache store, as shown in the figure below.
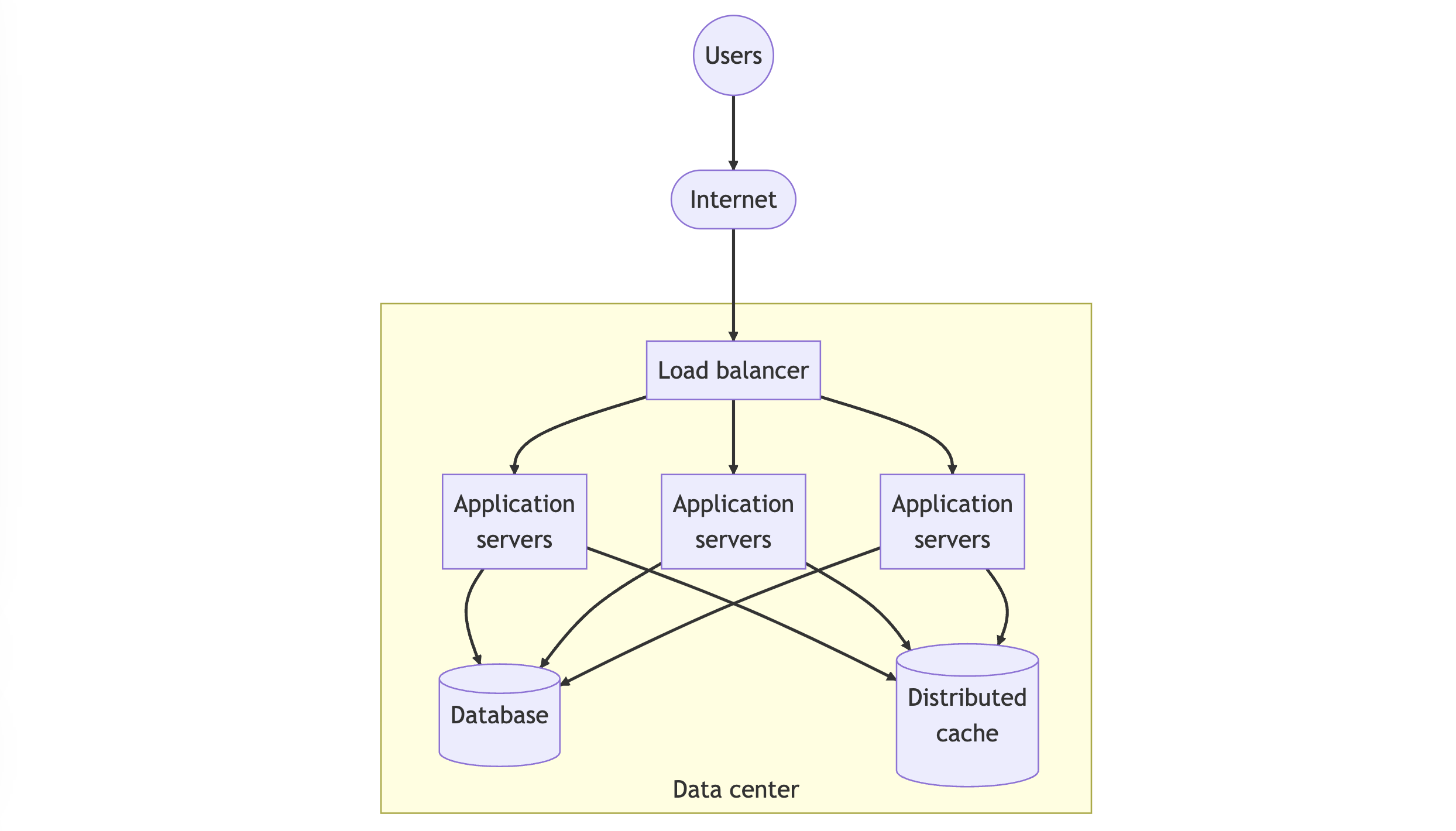
To incorporate a caching layer, your code must perform two tasks:
- Verify if the record is present in the cache before querying the database
- Determine the record's time-to-live (TTL) in the cache to remove it (invalidate). As a result, your application must tolerate stale results for clients
Even though a caching layer can be implemented, there are still scenarios where systems require fast access to vast amounts of data that a single database cannot handle. In such cases, a distributed database is necessary.
Distributed database
There are 2 major types of distributed databases which are distributed relational databases and distributed non-relational databases.
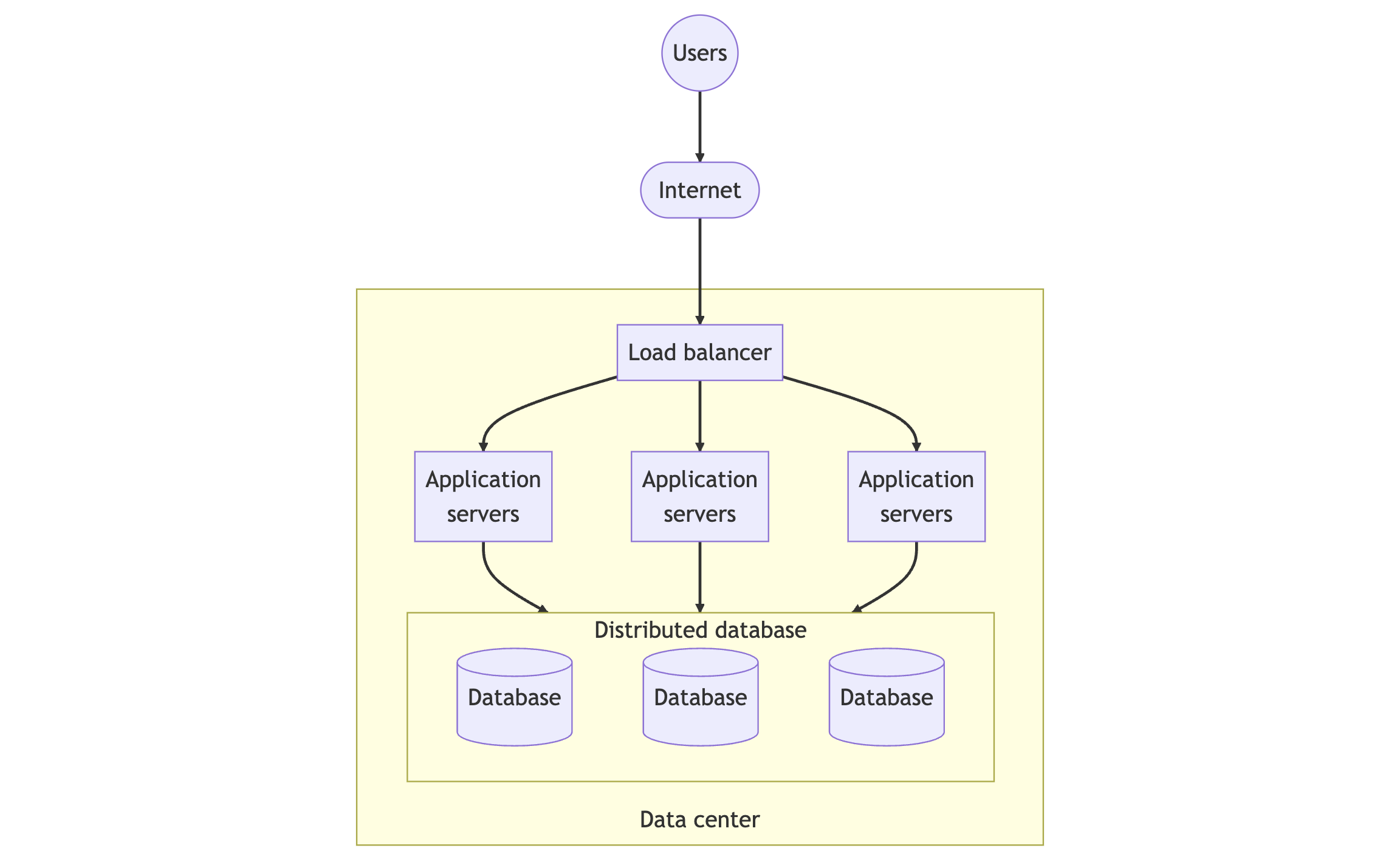
Note that the above diagram removes the distributed cache for simplicity.
Distributed relational database
The distributed relational database enables the scaling out of relational databases by storing data on multiple disks queried by multiple replicas of the database engine. From the application's perspective, it only views these engines as a single database. Examples of this include SQL Server and Oracle.
Distributed non-relational database
A distributed non-relational database distributes data among multiple nodes, each running its own database engine and having locally attached storage. The location of data is typically determined using a hash function applied to database keys, while the application views it as a single database. Examples of this type of database include MongoDB, Neo4j, and Cassandra.
Multiple processing tiers
It is typical for an API to fetch data from various sources, aggregate it, and return the result. To achieve this, it's common to split complex computing processes into multiple services, also known as microservices. This architecture enables independent scaling of services by replicating and load balancing each service.
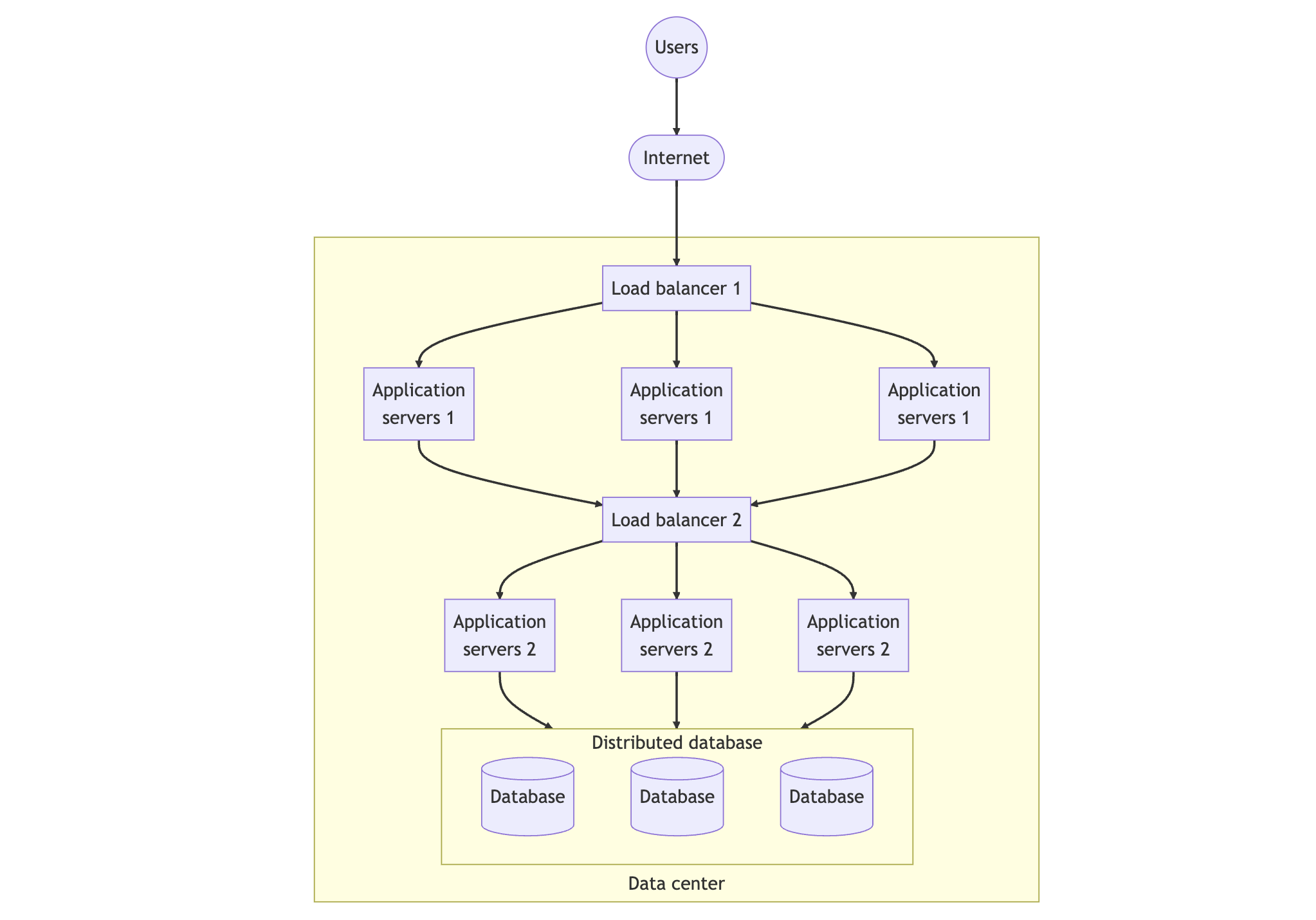
For web applications, the commonly used design pattern is the Backend for Frontend (BFF). This pattern offers a service for mobile and web clients that utilizes a core service that provides database access. Each service can be scaled independently based on its traffic.
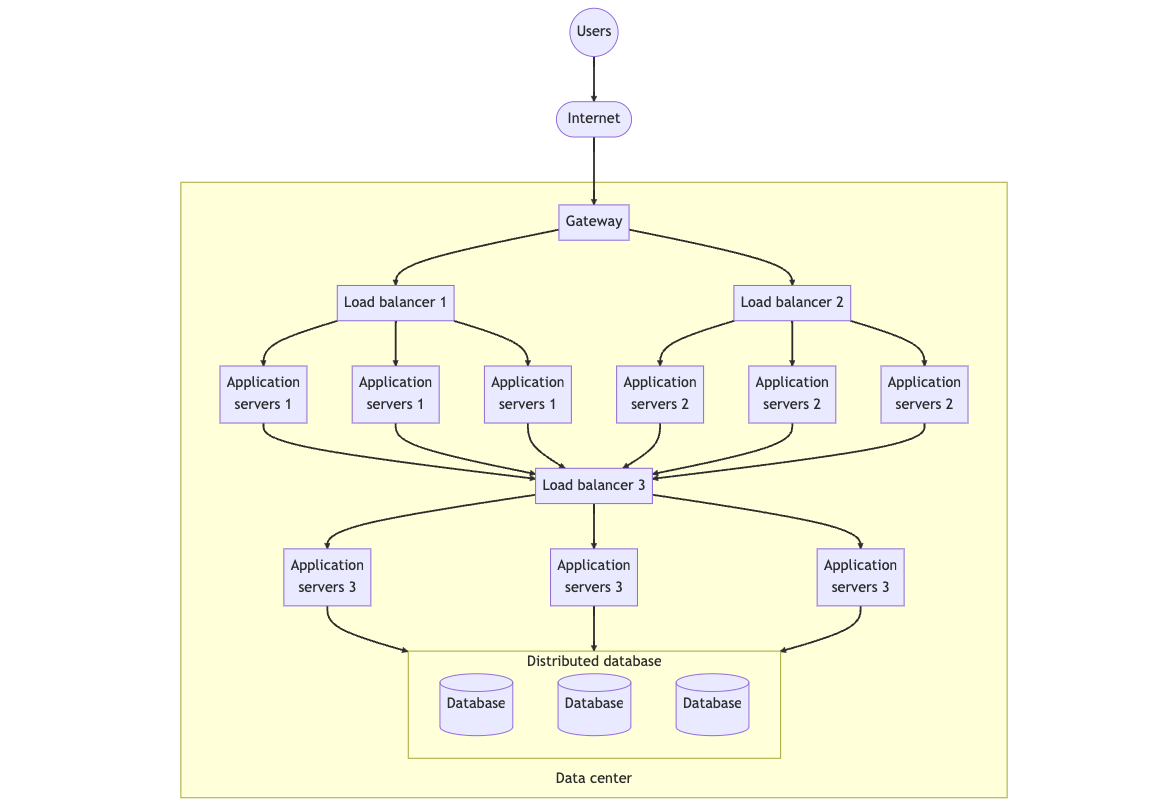
Note that the above diagram removes the distributed cache for simplicity.
Distributed queue
To provide faster responses to users, it is necessary to optimize the retrieval process for data that cannot be quickly retrieved from the cache. This involves acknowledging the receipt of requests and storing them in a remote queue for later processing.
Distributed queues are used to transmit data from one service to another. Compared to writing to a database, writing messages to a queue is much faster, thus enabling faster acknowledgment of requests and improving overall responsiveness. However, this approach requires the deployment of another service, the consumer, to read messages from the queue and write data to the database.
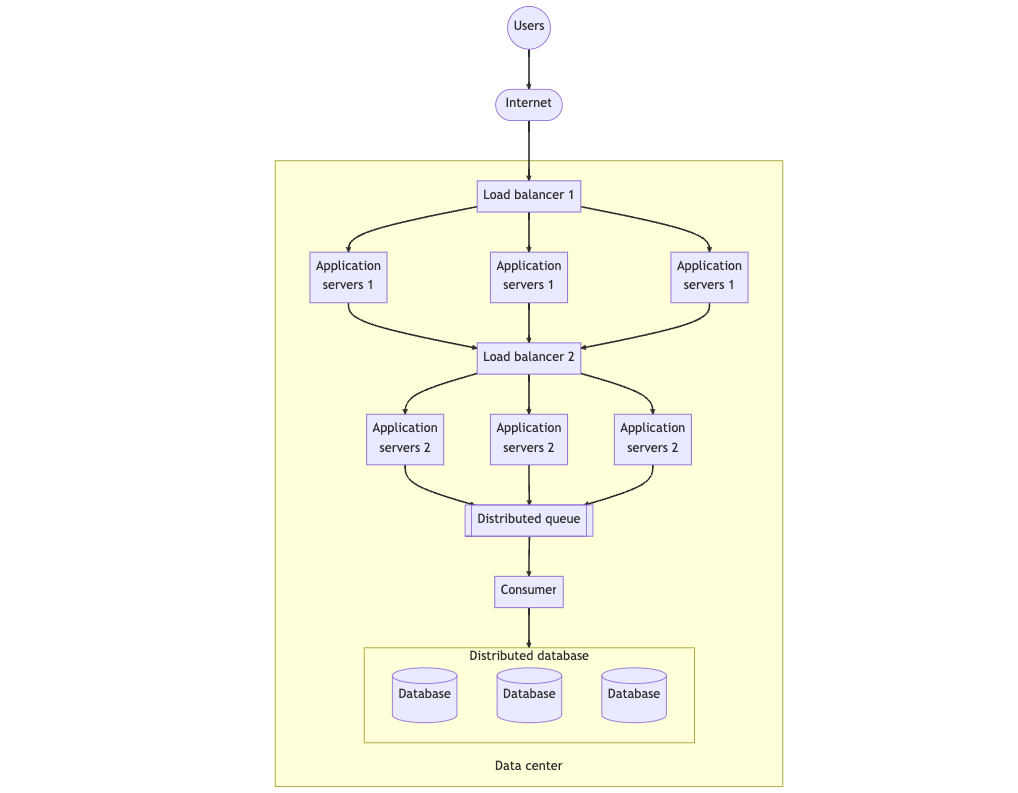
Note that the above diagram removes the distributed cache for simplicity.
Hardware scalability
Balancing performance, scalability, and costs is essential when scaling an application. Amdahl's law (opens in a new tab) provides some guidelines for optimizing performance:
- If only 5% of the code runs serially and the rest runs in parallel, adding more than 2048 cores will not significantly improve performance.
- If 50% of the code runs serially and the rest runs in parallel, adding more than 8 cores will not significantly improve performance.
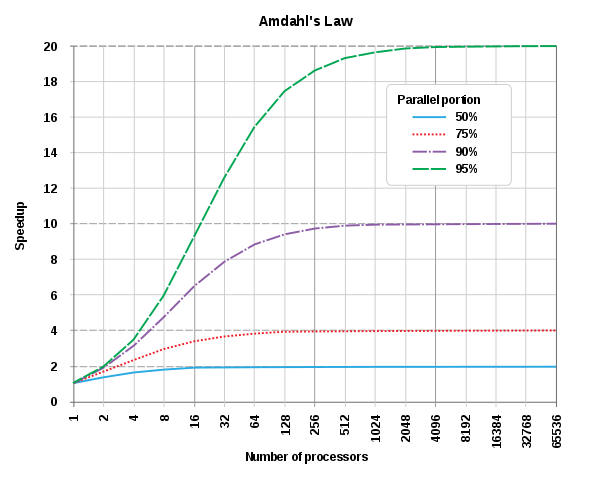
To achieve scalability, it's crucial to have efficient and multithreaded code. Simply running single-threaded code on a node with more cores won't enhance performance; also, increasing hardware may raise costs without necessarily improving performance. Conducting experiments and benchmarks provide valuable data to determine appropriate hardware and validate costs.
Keynotes
- Scaling out
- Adding more instances to handle increased traffic
- Stateless services make scaling out easier
- Scaling with caching
- Caches retrieve commonly accessed data to reduce querying time
- Distributed caching is effective for distributed systems
- Distributed database
- Distributes data across multiple nodes, each with its own storage
- Can be relational or non-relational
- Multiple processing tiers
- Splitting complicated computing processes into multiple services
- Allows for independent scaling and load balancing
- Increasing responsiveness
- Acknowledge receipt of requests faster by storing them in a remote queue for subsequent processing
- Hardware scalability
- Efficient and multithreaded code is important
- Adding more hardware might not always improve performance
- Running experiments and benchmarks can help select suitable hardware and justify costs.