
Introduction
Caching reduces the cost of computing expensive queries, makes the results reusable by subsequent requests, and increases the system's capacity to handle more workloads. There are 2 major types of caching levels:
- Application caching: This type of caching occurs at the application level where business logic code manages cache access
- Web caching: This type of caching happens at the internet level where the HTTP protocol is used to perform caching
Application caching
Application caching allows storing computed results in memory to be reused by subsequent requests, reducing the computation of constructing expensive objects. Distributed cache engines like Redis and Memcached are commonly used as databases for application caching. Common use cases of application caching include storing results of database queries, rendered web pages, and user session data.
There are 2 types of caching strategies including cache-aside pattern and cache-through pattern. The basic data flow of the cache-aside pattern is:
- The application service first checks the cache for data availability. If the data is available, the cached results are returned, which is called a cache hit
- If the data is not found in the cache, the application service retrieves the data from the database, writes the results to the cache store, and then returns the results. This is called a cache miss
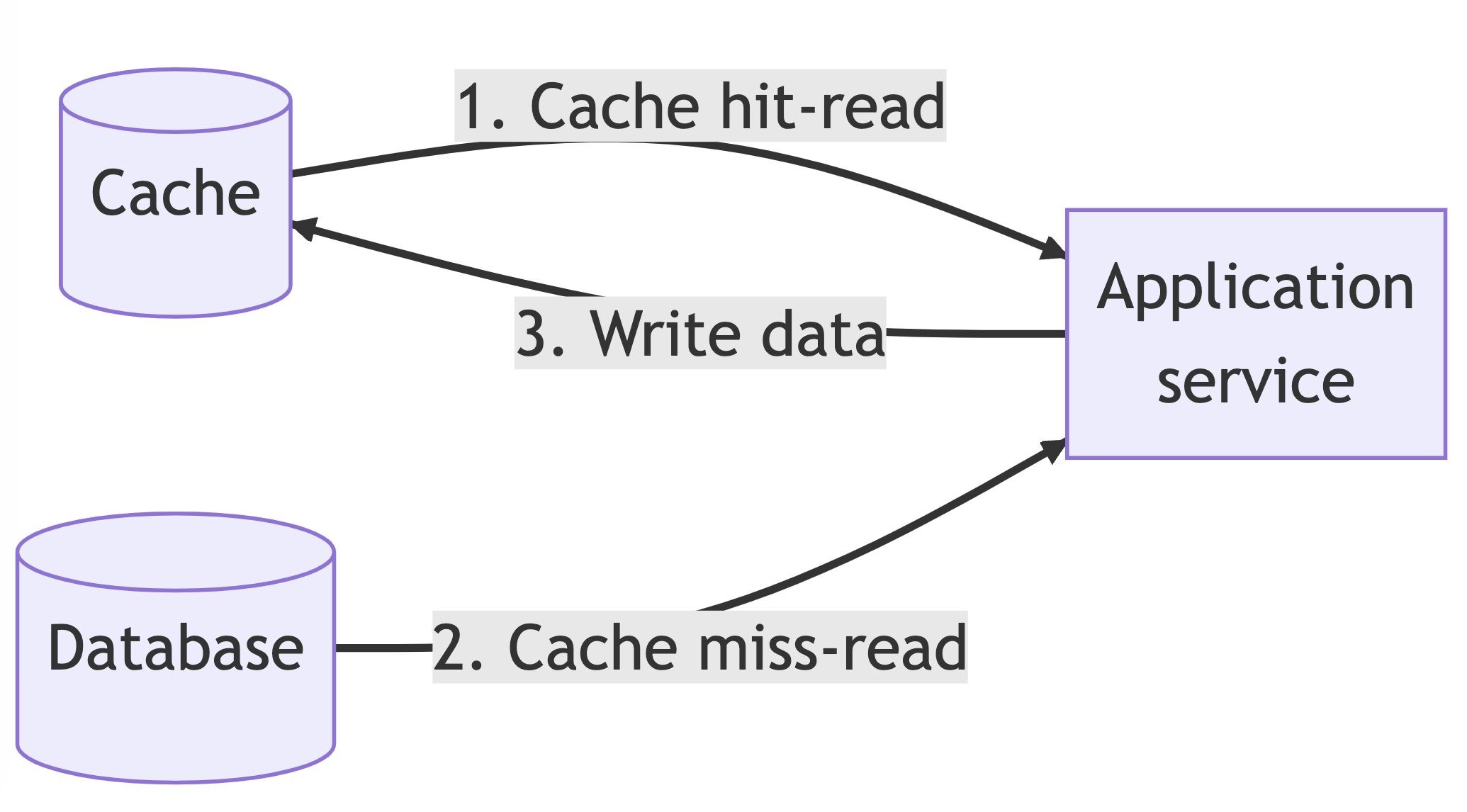
Data stored in the cache is associated with a key and a time to live (TTL) value, which tells the cache how long to retain the data. Once the TTL time is up, the data becomes stale, and the application service needs to query the data from the database or recalculate the results. To manage the cache store's size, a caching policy is used to determine which cache entries should be evicted for newer results, with Least Recently Used (LRU) being a common policy.
The cache-hit rate depends on the update rate of the results and the cost of calculating the results. If a system has more reads than updates, it's ideal for caching. After implementing a caching solution, it's essential to monitor the cache usage to ensure the cache hit and miss rates align with the design.
Another common caching pattern is cache-through, which is not commonly found on the internet because I named it myself.
The cache-through pattern contrasts with the cache-aside pattern. In cache-through, the application service reads from the cache and writes to the cache. There are 3 common designs in cache-through with the following data flow:
Read-through
- When the application service intends to read, it first checks the cache to determine if the data is available. If found, it returns the cached results
- If the data is not available in the cache, a loader is activated to fetch the data from the database. The results are loaded into the cache before being returned to the application service
Write-through
- The application service initiates a write operation by writing the data to the cache
- After the cache is updated, a writer is triggered to write the updated data to the database. The writer waits for the database to be updated and then responds to the application service
Write-behind
Similar to write-through, but the writer responds to the application service immediately, without waiting for the database to be updated.
For more defails about these 3 common designs, you can read this article (opens in a new tab).
The cache-aside pattern requires the application to handle cache misses, while the cache-through pattern only involves the cache for reads and writes, with the cache managing data updates. While cache-through is dependent on cache technology, cache-aside can be implemented in the application.
In scalable systems, the cache-aside pattern is the more common approach as it allows application service to access data even if the cache is unavailable.
Web caching
Numerous cache stores exist on the internet. Web content is often cached by your web browser, your organization may implement its own caching layer, and your Internet Service Provider (ISP) caches certain responses to common requests. Additionally, the service you are requesting likely has its own caching layer.
Cache results generally consist of the results of GET requests, and the request's URI serves as the cache key. By utilizing HTTP caching directives, the services you request can manage what results are cached and for how long. The following table displays some of the most common HTTP headers utilized for caching control.
| Header | Purpose | Example values |
|---|---|---|
| Cache-Control | Specify how to use the cahse; used by client requests, service responses | no-store, no-cache, private, public, max-age |
| Expires | How long the cache result is retained | Sat, 17 Feb 2023 01:02:03 GMT |
| Last-Modified | Used to compute the retention periods | Sat, 17 Feb 2023 01:02:03 GMT |
| Etag | Used to check if a cached item is valid | "model-2-prediction-2023-01-01" |
You can read this article (opens in a new tab) for more details.
Keynotes
- Caching reduces the cost of computing expensive queries and increases the system's capacity to handle more workloads
- There are two major types of caching levels: application caching and web caching
- Cache-aside pattern requires the application to handle the cache miss cases, while cache-through pattern only talks with the cache for reads and writes
- Cache results are usually associated with a key and a time to live (TTL) value. The TTL tells the cache how long to retain the data, and after this TTL time, the value is stale
- HTTP caching directives can be used to control caching, such as max-age, must-revalidate, and no-cache