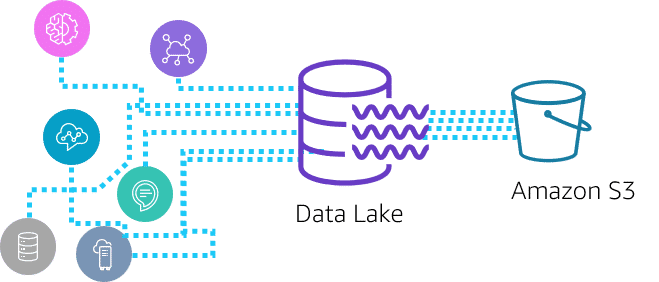
The whole field of ML revolves around data. Data helps you make strategic business decisions and understand your customers deeper. This post focuses on the recommended practical AWS workshops/courses you should take to gain fundamental to advanced understanding and skills to create a data pipeline. You can skip the introduction of AWS courses. You only need to get the idea of the data pipeline as a whole.
Create a data repository
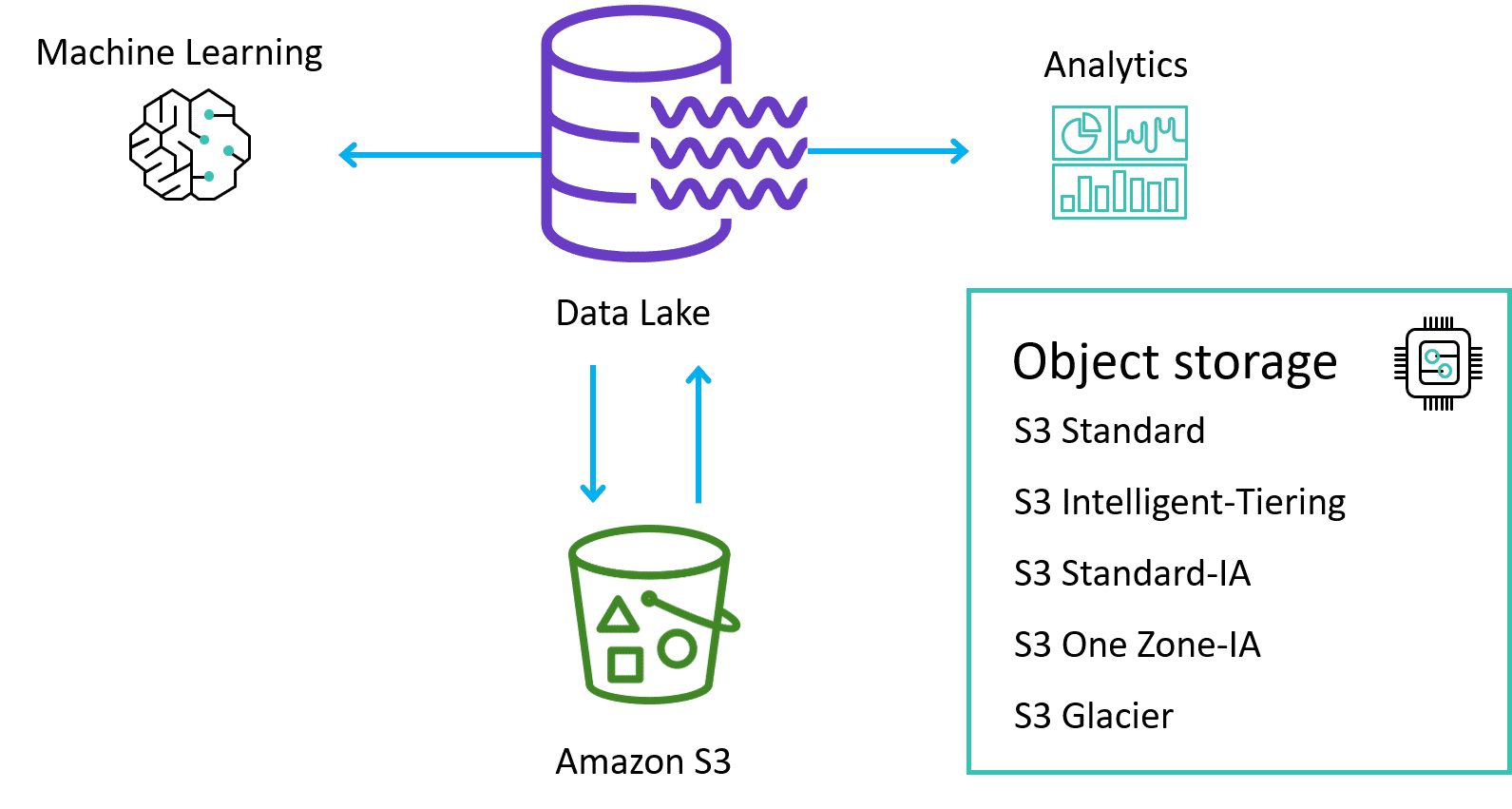
Lake Formation
After collecting the data, now it's time to store your data in a centralized repository. With a data lake, you can store structured and unstructured data. Lake Formation is a data lake solution, and S3 is the preferred storage option for data science processing on AWS.
To learn more, refer to:
- AWS Lake Formation Workshop (opens in a new tab). This workshop provides a tutorial about:
- Glue basics
- Lake Formation basics
- Integration with EMR
- Handling real-time data using Kinesis
- Note: In the
Kinesis Data Generator,Create a Data Stream, andCreate Stream Tablesections, log in with your admin user because creating a CloudFormation stack requires permissions related to IAM, Lambda, S3, Glue, etc.
- Note: In the
- Glue to Lake Formation migration: This part has some problems with created user's permission and outdated AMI ID. You can skip this part
- Data Engineering Immersion Day (opens in a new tab). This workshop covers:
- Streaming data analytics using Kinesis, Glue, and MSK
- Data ingestion using DMS
- Transforming data using Glue
- Query and visualize data using Athena, QuickSight, and SageMaker
- Data lake automation using Lake Formation
FSx for Lustre
When your training data is already in S3, and you plan to run training jobs several times using different algorithms and parameters, consider using FSx for Lustre, a file system service. The first time you run a training job, FSx for Lustre copies data from S3 and makes it available to SageMaker. You can use the same FSx file system for subsequent iterations of training jobs, preventing repeated downloads of common S3 objects.
To learn more, refer to:
- Amazon Web Services HPC Workshops (opens in a new tab)
- This workshop is about High-Performance Computing
- Kubernetes and EKS (opens in a new tab)
- This workshop explores multiple ways to configure VPC, ALB, and EC2 Kubernetes workers and Elastic Kubernetes Service
Elastic File System
Alternatively, if your training data is already in Elastic File System (EFS), we recommend using that as your training data source. EFS can directly launch your training jobs from the service without data movement, resulting in faster training start times. For example, a data scientist can use a Jupyter notebook to do initial cleansing on a training set, launch a training job from SageMaker, then use their notebook to drop a column and re-launch the training job, comparing the resulting models to see which works better.
To learn more, refer to:
- Cloud File Storage the AWSome Way! (opens in a new tab)
- Kubernetes and EKS (opens in a new tab)
- This workshop explores multiple ways to configure VPC, ALB, and EC2 Kubernetes workers and Elastic Kubernetes Service
Training load time comparison
When choosing a file system, take into consideration the training load time. The table below shows an example of some different file systems and the relative rate they can transfer images to a compute cluster. Relative speed compares the relative (to EFS) images per second that each file system can load.
| File system | Relative Speed |
|---|---|
| S3 | <1.0 |
| EFS | 1 |
| EBS | 1.29 |
| FSx | >1.6 |
Implement a data ingestion solution
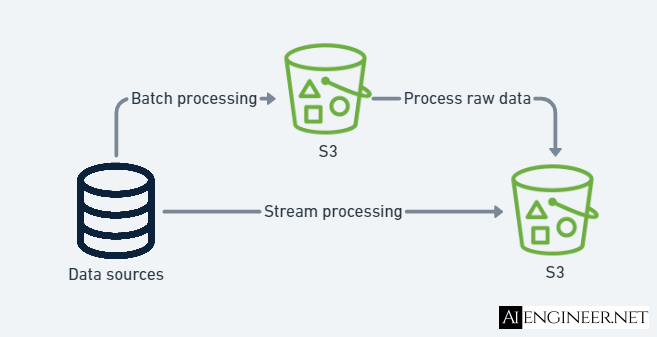
In some cases, data resides outside the data repository solution like on-premises storage. To use this data, we need to ingest it into an AWS storage service like S3. This post will focus on the cloud services to implement two types of data ingestion solutions which are Batch processing and Stream processing.
You can skip the introduction of AWS courses. You only need to get the idea of implementing a data ingestion solution and its purpose.
Batch processing
The ingestion layer periodically collects and groups source data with batch processing and sends it to a destination like S3. Batch processing is used when there is no real need for real-time or near-real-time data because it is easier and more affordably implemented than other ingestion options.
Options to collect and group source data and send it to S3:
- Use DMS (Database Migration Service) to read historical data from source systems, such as relational database management systems, data warehouses, and NoSQL databases, at any desired interval
Options to process raw data are:
- Use Glue for ETL processes (categorize, clean, enrich, move)
- Use Step Functions to automate ETL tasks that involve complex workflows
Processed data will be stored in a data lake/warehouse solution like S3.
To learn more, refer to:
- AWS Database Migration Workshop (opens in a new tab). This workshop covers:
- SQL Server to Aurora (MySQL)
- SQL Server to Aurora (PostgreSQL)
- SQL Server to SQL Server running on RDS
- SQL Server to S3
- Oracle to Aurora (PostgreSQL)
- Oracle to Oracle running on RDS
- Monitoring DMS Migrations
- AWS Glue Studio Workshop (opens in a new tab). This workshop covers:
- Create a Glue job
- Joining tables using a Glue job
- Note: When creating the Glue job, adding partition key in a
Apply Transformstep might raise the errorpy4j.protocol.Py4JJavaError: An error occurred while calling o143.pyWriteDynamicFrame.: scala.MatchError: (null,false) (of class scala.Tuple2)
- Note: When creating the Glue job, adding partition key in a
- Schedule a Glue job
Stream processing
Stream processing includes real-time processing and involves no grouping. Data is sourced, manipulated, and loaded as soon as it is created or recognized by the data ingestion layer. It requires systems to constantly monitor sources and accept new information. You might want to use it for real-time predictions or analytics that need continually refreshed data, like real-time dashboards.
Kinesis, Confluent Cloud, and MSK are the candidates for stream processing. Read this article (opens in a new tab) to compare Kinesis and MSK. Read this article (opens in a new tab) to compare Confluent Cloud and MSK.
- Use Kinesis to capture and ingest fast-moving data
- Kinesis video streams
- Kinesis data streams
- Kinesis data firehose
- Kinesis data analytics
To learn more, refer to:
- Real Time Streaming with Amazon Kinesis (opens in a new tab). This workshop covers:
- Produce data to Kinesis Data Stream by:
- Using Amazon SDK for Kinesis
- Using Kinesis Producer Library
- Produce data to Kinesis Data Stream using in-memory table created in an Apache Zeppelin notebook with Apache Flink as the stream processing engine (so-called Kinesis Data Analytics)
- Process streaming data using Kinesis Data Firehose and Lambda
- The data flow looks like: Streaming data --> Kinesis Data Stream --> Kinesis Delivery Stream (Data Firehose) --> Lambda (to preprocess data) --> S3
- Streaming data and Kinesis Data Stream are in the ingestion layer
- Kinesis Delivery Stream and Lambda are in the processing layer
- Clean, aggregate, enrich, and visualize data using Kinesis Data Analytics and OpenSearch (ElasticSearch)
- Process streaming data from Kinesis Data Stream using only Lambda
- In Lambda code, parse
vendorIdasstringinitemobject
- In Lambda code, parse
- Preprocess streaming data from Kinesis Data Stream using Kinesis Client Library (KCL) before passing the data to the processing logic
- KCL takes care of complex tasks associated with distributed processing, such as loading balance record processing across many instances
- Produce data to Kinesis Data Stream by:
- Streaming Analytics Workshop (opens in a new tab). This workshop covers:
- End-to-end scalable streaming architecture to ingest, analyze, and visualize streaming data using Kinesis with a very detailed explanation
- Deploy a Flink application using the Kinesis Data Analytics Studio Zeppelin notebook
- End-to-end streaming architecture that combines batch and streaming aspects in one uniform Apache Beam pipeline
- Note: When creating the Cloud Formation stack, you might need to update the stack template to avoid a timeout error on creating resources. In the stack template, you should change the Timeout property of
Cloud9DevEnvironmentKinesisReplayBuildPipelineWaitConditionAC504110andBeamConsumerBuildPipelineWaitCondition71C56893to 3600, then recreate the stack
- Note: When creating the Cloud Formation stack, you might need to update the stack template to avoid a timeout error on creating resources. In the stack template, you should change the Timeout property of
- Typical Kinesis solutions (opens in a new tab)
- Building Data in Motion Applications with Confluent on AWS (opens in a new tab)
- Note: This workshop requires your credit card credentials to use Confluent
Implement a data transformation solution
This post will focus on the AWS's resources you might need to implement data transformation solutions. You can skip the introduction of AWS courses. You only need to get the idea of implementing a data transformation solution and its purpose.
The raw data ingested into the data repository is usually not ML-ready as-is. The data needs to be transformed and cleaned, including deduplication, incomplete data management, and attribute standardization. Data transformation can also involve changing the data structures, usually into an OLAP model to facilitate easy querying of data. The general process of using AWS's cloud services looks like this:
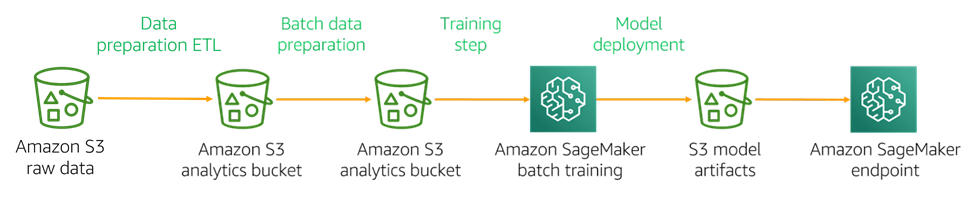
Data preparation ETL
Data preparation ETL might deal with vast amounts of data. Distributed computation frameworks like MapReduce and Apache Spark provide a protocol of data processing and node task distribution and management. They also use algorithms to split datasets into subsets and distribute them across nodes in a compute cluster.
Using Apache Spark on EMR is one cloud-based solution for Data preparation ETL. EMR supports many instance types with proportionally high CPUs with increased network performance, which is well suited for HPC (high-performance computing) applications.
To learn more, refer to:
- Amazon EMR Developer Experience Workshop (opens in a new tab)
- Note: This workshop requires you to create an AWS organization. Make sure you have the permission to create one in AWS Organizations service (opens in a new tab)
- ETL on Amazon EMR Workshop (opens in a new tab). This workshop covers:
- Submitting and monitoring Spark-based ETL work to an EMR cluster
- Running Hive on the EMR cluster
- Running Pig on EMR cluster
- Using SageMaker in EMR notebooks
- Orchestrating EMR with Step Functions
- EMR cluster automatic scaling
Batch data preparation
Datasets required for ML applications are often pulled from database warehouses, streaming input, or centralized data lakes. You can use S3 as a target endpoint for the training datasets in many use cases.
ETL processing services (Athena, AWS Glue, Redshift Spectrum) are functionally complementary. In addition to transforming data with services like Athena and Redshift Spectrum, you can use services like AWS Glue to provide metadata discovery and management features.
The choice of ETL processing tool is primarily dictated by the type of data you have. For example, tabular data processing with Athena lets you manipulate your data files in S3 using SQL. If your datasets or computations are not optimally compatible with SQL, you can use AWS Glue to run Spark jobs (Scala and Python support).
To learn more, refer to:
- Amazon Athena Workshop (opens in a new tab). This workshop covers:
- Basic Athena capabilities (query, ETL with CTAS, workgroups)
- Federated query
- User defined functions (UDF)
- Deploying custom connector
- Text analysis using UDF
- SageMaker endpoint integration
- Redshift Immersion Labs (opens in a new tab)
Example solution for healthcare data
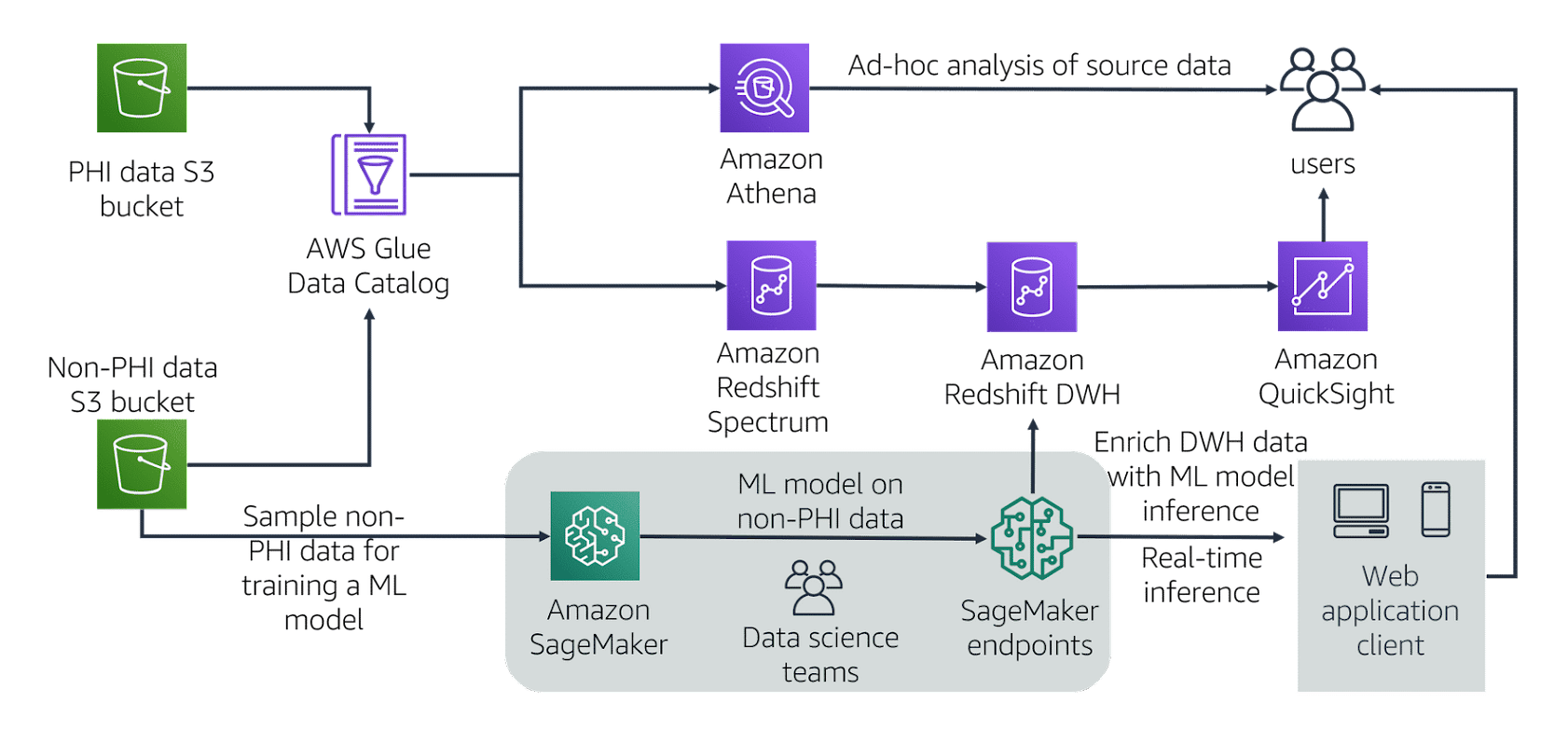
This architecture builds a scalable analytical layer for healthcare data. Customers can:
- Store a single source of data in S3
- Perform ad hoc analysis with Athena
- Integrate with a data warehouse on Redshift
- Build a visual dashboard for metrics using QuickSight
- Build an ML model to predict readmissions using SageMaker
Customers avoid building redundant copies of the same data by not moving the data around and connecting to it using different services.
To learn more, refer to:
- QuickSight Workshops (opens in a new tab)
- Amazon Quicksight Workshop Covid 19 Data Analysis (opens in a new tab)
Ending
This post covered the typical data pipeline for an ML application in production. In large-scale applications, the data pipeline might require some data-streaming infrastructure, a feature store that can share features among teams, etc. The data transformation part might require some automation and parallelism to transform data quickly to serve the online ML models.