Deploying models is easy, and deploying models reliable is hard. The complex parts of deploying models to production include setting up the infrastructure to keep the system 99% uptime, notifying the right person when something goes wrong, detecting what went wrong, and fixing it seamlessly. When it comes to the deployment, there are several things we should consider as follows.
- Inference latency
- Deployment pattern: monolith vs. microservices, batch prediction vs. online prediction, cloud vs. edge deployment
- Deployment strategies: rolling, canary, blue/green, etc.
- High availability: redundancy, disaster recovery
- Scalability: scale in/out, latency, high-volume predictions
- Testability: unit tests, integration tests, system tests, etc.
- Security: data provider constraints, customer privacy, data/model encryption, access control, etc.
- Maintenance and monitoring: logging, feedback loop, concept drift, system metrics, etc. We will discuss this section in the next post.
Inference latency
If we want to make the inference faster, we can do the following:
- Model compression to make the model smaller
- Low-rank factorization: replace high-dimensional tensors with lower-dimensional tensors
- Knowledge distillation: train a small model to mimic a larger model or ensemble of models, and deploy the small model
- Pruning: remove parameters that are close to 0
- Quantization: use fewer bits to represent its parameters
- Inference optimization to make the model inference faster
- Use libraries like TensorRT to optimize the model computation graph
- Use ML to optimize ML models: cuDNN autotune, autoTVM (opens in a new tab)
- Use TensorFlow.js (opens in a new tab), Synaptic (opens in a new tab), brain.js (opens in a new tab), WebAssembly (opens in a new tab) to run model in browsers
- Hardware upgrade to run faster
- Use GPU and TPU
Please refer to [this Google docs file] for more details about the model compression, inference optimization, and hardware technologies for model inference, please refer to this Google docs file (opens in a new tab).
Deployment pattern
Deployment patterns could be in many contexts.
- Serving types: Batch prediction vs. Online prediction
- Computing technologies: Cloud computing vs. Edge computing
- Architecture: Monolith vs. Microservices
For Batch prediction vs. Online prediction, Cloud computing vs. Edge computing, please refer to the post Intro To Machine Learning Systems Design - Overview in this The Ultimate Machine Learning System topic.
Monolith vs. Microservices
On the one hand, the monolith is the default architecture for creating a software application. It has some known challenges, such as handling a vast codebase, adopting new technology, scaling, deployment, implementing new changes, etc. On the other hand, microservices offer significant benefits such as increased scalability, flexibility, agility, etc. The table below compares the difference between these two architectures.
| Monolith | Microservices | |
|---|---|---|
| Definition | Monolithic architecture (MoA) composes everything into one piece. | Microservices architecture (MiA) separates an extensive application into smaller independent parts, each part having its own responsibility. |
| Advantages | - Simple to develop - Simple to deploy - Simple to scale by running multiple copies of app behind a Load Balancer - Good for small teams, small projects | - Easy to CI/CD for large apps - Each ms is small - Improve fault isolation - No long-term commitment to a technology stack |
| Disadvantages | - App is hard to understand and modify - Continuous deployment is complex - Can't scale with an increasing data volume because each copy accesses all of the data - Can't scale each component independently - Require long-term commitment to a technology stack | - Distributed system complexity: inter-service communication, inter-service requests, inter-service tests - Deployment complexity: multi-service deployment - Memory consumption: Each service runs on its own environment which might require its own instance |
Deployment strategies
Deployment strategies change or upgrade an application. Below are the steps of some common deployment strategies.
- In-place
- Make all instances offline
- Install the new version
- Make all instances online
- Rolling
- Make N instances offline
- Install the new version
- Make N instances online
- Continue with the next N instances
- Canary
- Similar to rolling, but it targets certain users to receive access to the new version, rather than specific servers
- This means we roll out the update to a small part of the users first. Once the change is accepted, the update is rolled out to the rest of the users
- Blue/green (A/B)
- Spin up a new infrastructure with the new version
- Test the new version before rerouting traffic to it
The table below compares the difference between some common deployment strategies.
| Strategy | Deploy time | Zero downtime | Deploy to | Rollback |
|---|---|---|---|---|
| In-place | 1 | No | Existing instances | Redeploy |
| Rolling | 2 | Yes | Existing instances | Redeploy |
| Canary | 2 | Yes | Existing instances | Redeploy |
| Blue/green | 4 | Yes | New instances | Swap endpoint |
High availability
High availability is a characteristic of a system that aims to ensure an agreed level of operational performance, usually uptime, for a designated period. To achieve high availability, we want to have the redundancy of computing resources to avoid a single point of failure and to prepare for the disaster.
The computing resources usually will be replicated in several instances. Those instances will even live in several physical buildings in different regions on different continents.
Disaster recovery
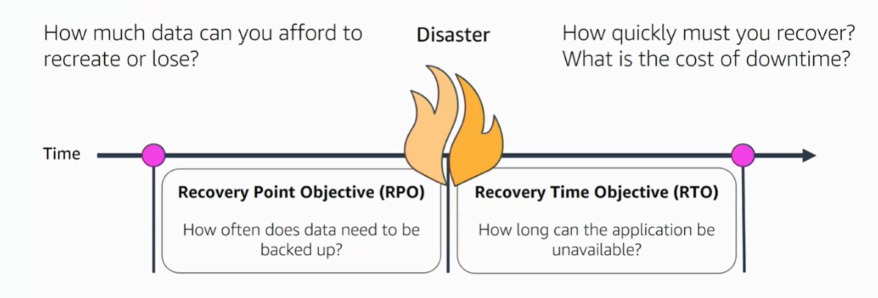
We have a disaster point at which the system is down in the disaster recovery context. To prepare for the disaster recovery, we need to answer some questions.
- Before the disaster, we need to define the Recovery Point Objective (RPO)
- How often does data need to be backed up?
- How much data can you afford to recreate or lose?
- After the disaster, we need to define the Recovery Time Objective (RTO)
- How long can the application be unavailable?
- How quickly must you recover?
- What is the cost of downtime?
The shorter the RPO and RTO are, the higher cost will be.
Scalability
When talking about scalability, we usually think about increasing and decreasing the number of computing instances in production, using a load balancer to distribute the loads at endpoints, caching for databases, etc.
Scaling
There are two main types of scaling, including vertical scaling and horizontal scaling. The table below compares the difference between them.
| Vertical scaling | Horizontal scaling | |
|---|---|---|
| Definition | Add more resources to a machine | Add more machines to the network |
| Advantages | - Easy to implement - Less management effort - Used for small teams and projects | - Easy to achieve fault tolerance - Easy to achieve high availability - Easy to scale in/out |
| Disadvantages | - Limited potential to improve network I/O, disk I/O - Replace server causes downtime - Risk of hardware failure | - Complicated architectural design: distributed system, load-balancing, communication - High management effort |
Caching
About caching, there are four main types of cache.
Application server cache: one server on one node has its own cache. When adding multiple nodes for servers, the LB sends requests to any nodes. The cache misses increase because each node is unaware of the cache in other nodes. To solve this, we use distributed cache.
Distributed cache: several nodes can access several caches. By using a consistent hashing function, each request can be routed to where the cache request could be found.
Global cache: we have a single cache space for all the nodes.
Content Delivery Networks (CDN): CDN is a group of servers/nodes that work together to distribute content based on physical location. CDN is used when serving a large amount of static content like HTML files, CSS files, images, videos, etc. The idea of the CDN is:
- The 1st person grabs the video, and the CDN caches the video to the closest physical nodes
- The subsequent users just grab the video from that closest node. The traffic doesn't always hit the original server/node
Container orchestration
Container orchestration is the automation of the operational effort required to run containerized services. This manages the container lifecycle, including provisioning, deployment, scaling, networking, load balancing, etc. When we deploy the system using containerization in the microservices architecture, the containerized application might operate hundreds or thousands of containers. This can introduce significant complexity if managed manually. Container orchestration makes that operational complexity manageable for development and operations by providing a declarative way of automating much of the work. There are several common container orchestration tools such as Kubernetes, Openshift, Hasicorp Nomad, Docker Swarm, Docker Compose, etc.
Test in production
There are several ways of testing in production.
- Test internally first
- Use features even as they are in development
- Share internally before externally
- Shadow testing
- New model in parallel with the existing system
- New model's predictions are logged but not shown to users
- Switch to a new model when results are satisfactory
- Canary testing
- New model alongside with existing system
- Some traffic is routed to the new model
- Slowly increase the traffic to the new model
- A/B testing
- New model alongside with existing system
- A percentage of traffic is routed to a new model based on routing rules
- Control target audience and monitor any statistically significant differences in user behavior
- Can have more than two versions
- Interleaved experiments
- Especially useful for ranking systems and recommendation systems
- Take recommendations from both models A and B
- Mix them and show them to users
- See which recommendations are clicked on
Ending
Deployment is more engineering, with much of the knowledge transferred from DevOps or Software Engineering in general. Each aspect we covered in this post plays an equally important role in the deployment process. In the next post, we will talk about another essential factor: maintenance and monitoring.