
Many distributed systems are designed to operate synchronously, but some systems are implemented to use asynchronous communication. In these systems, requests are sent to an intermediary messaging service, and the system immediately returns responses to clients without waiting for the messaging service to respond. The requests are then processed by their intended destinations after being received from the messaging service. RabbitMQ is one of the most commonly used open-source messaging systems.
Messaging system components
A messaging system typically includes the following components:
| # | Component | Description |
|---|---|---|
| 1 | Message queue | Queue that stores messages |
| 2 | Producer | Service that sends messages to queues |
| 3 | Consumer | Service that receives messages from queues |
| 4 | Message broker | Manage >= 1 queues |
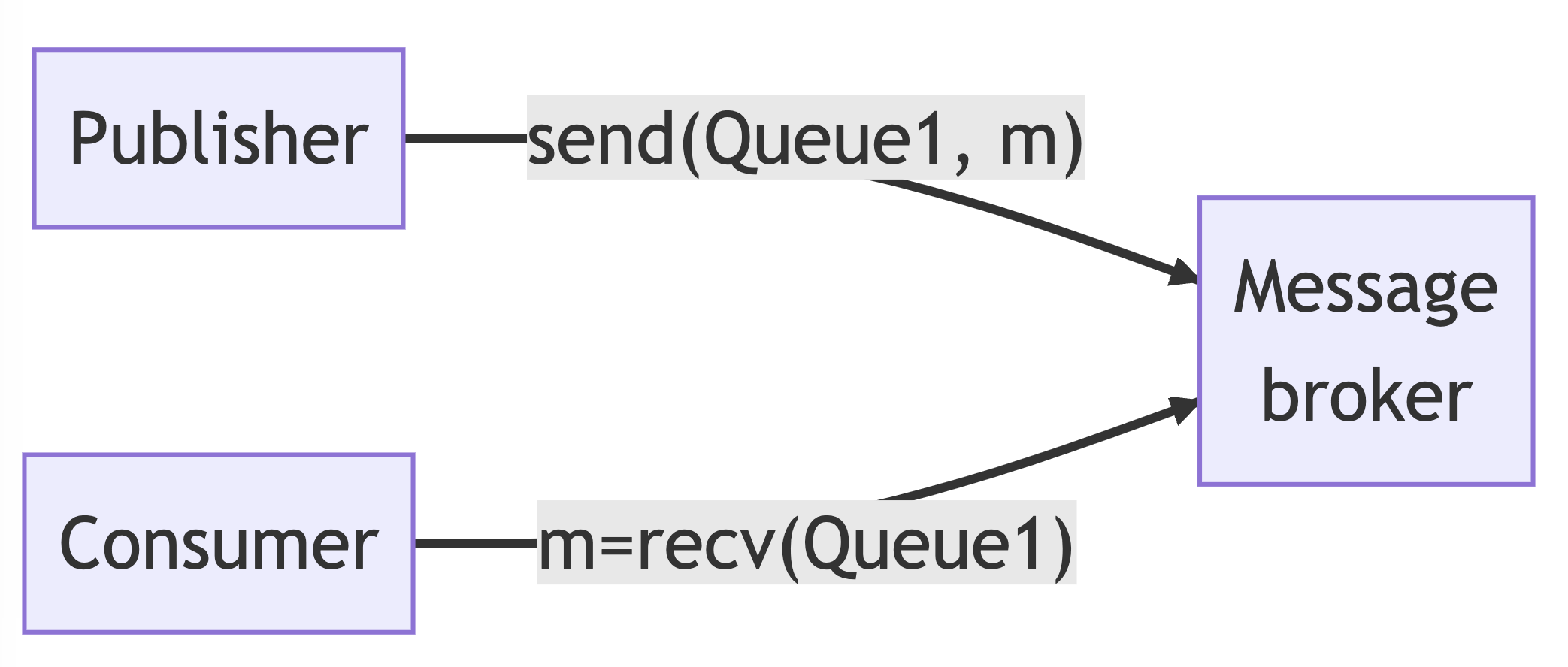
The main tasks performed by a message broker include:
- Receiving messages from producers and adding them to a queue
- Returning messages to consumers and managing message retention
Messaging systems typically:
- Allow multiple producers to send messages to a single named queue
- Allow multiple consumers to consume messages from that same-named queue
When communicating with the message broker, producers must wait for an acknowledgment to confirm that the message has been received. There are two modes of communication between the message broker and consumers:
| Consumer Mode | Description |
|---|---|
| Polling (Pull) | Consumers send requests to the broker to check for the next available message, and the broker returns the message |
| Push | Consumers provide the broker with a callback function, which the broker can call when a message becomes available |
The push mode is more efficient as the message broker does not need to process a large number of polling requests from multiple consumers.
Once a consumer receives a message, it sends an acknowledgment to indicate that it has received the message. This allows the broker to mark the message as delivered and remove it from the queue. There are two types of message acknowledgments on the consumer side, which are:
| Consumer Acknowledgement Mode | Description |
|---|---|
| Automatic | Acknowledges the receipt before processing the message |
| Manual | Processes the message successfully before acknowledging the receipt |
Using manual ack mode may introduce higher latency compared to auto ack mode, but it provides the benefit of avoiding situations where a message is delivered but not processed. If a message is not acknowledged by the consumer, it remains in the queue and can be delivered to other consumers.
Message persistence
To ensure messages are not lost in case of a messaging system crash, one solution is to use persistent queues.
Persistent queues are implemented by storing messages in both memory and disk. When a message is received, it is stored in both memory and disk before the receipt acknowledgment is sent to the producers to prevent message loss. This, however, increases the latency of storing messages to ensure data safety. When retrieving messages, they are still retrieved from memory for faster access.
Publish-subscribe broker
A publish-subscribe broker is a messaging broker that implements the publish-subscribe architecture, which has the following characteristics:
- It allows for one-to-many message delivery
- The producer, also known as the publisher, sends messages to a named queue in the broker, which is referred to as the topic
- Multiple consumers, also known as subscribers, can retrieve messages from the same topic
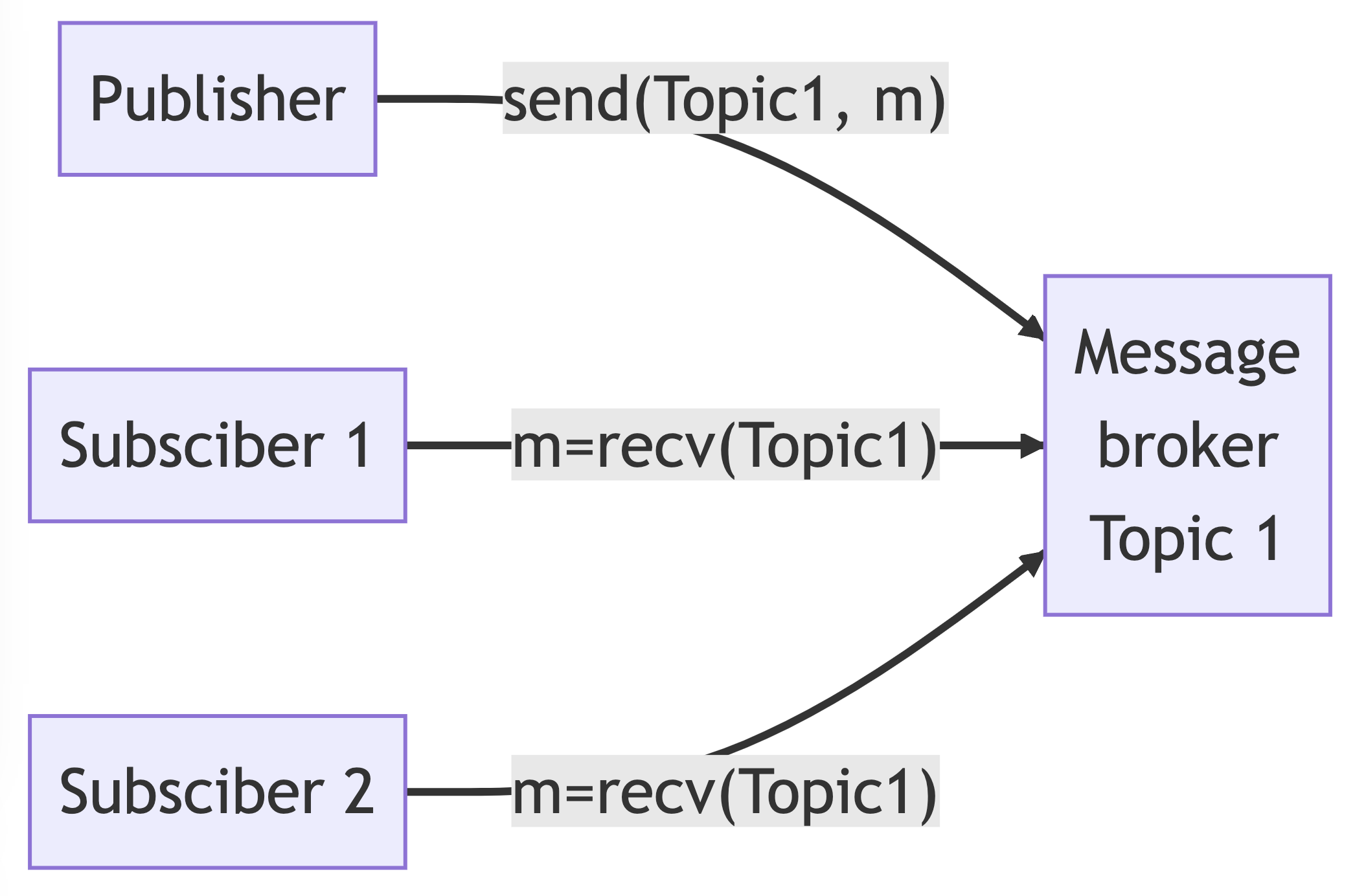
An example use case for this architecture is when a Machine Learning Inference service predicts requests from clients, and a Logging service also wants to receive the requests from clients to construct training data for later use. Clients can send requests to a Prediction topic, and both the Machine Learning Inference service and Logging service can subscribe to the Prediction topic.
However, there are some known issues with this implementation. For example, the broker needs to deliver each message to all subscribers and retain the message until all subscribers have processed it. Implementing push mode for consumers is the most efficient solution for a publish-subscribe broker.
Publish-subscribe messaging systems are a key component in distributed event-driven systems, which we will discuss in a future post.
Leader-follower broker
If there is only one message broker in the system, it can become a single point of failure. To avoid this, we can replicate the brokers on multiple nodes using a leader-follower architecture. Messages published to the leader are copied to the follower(s), and messages consumed by the leader are deleted from the follower(s).
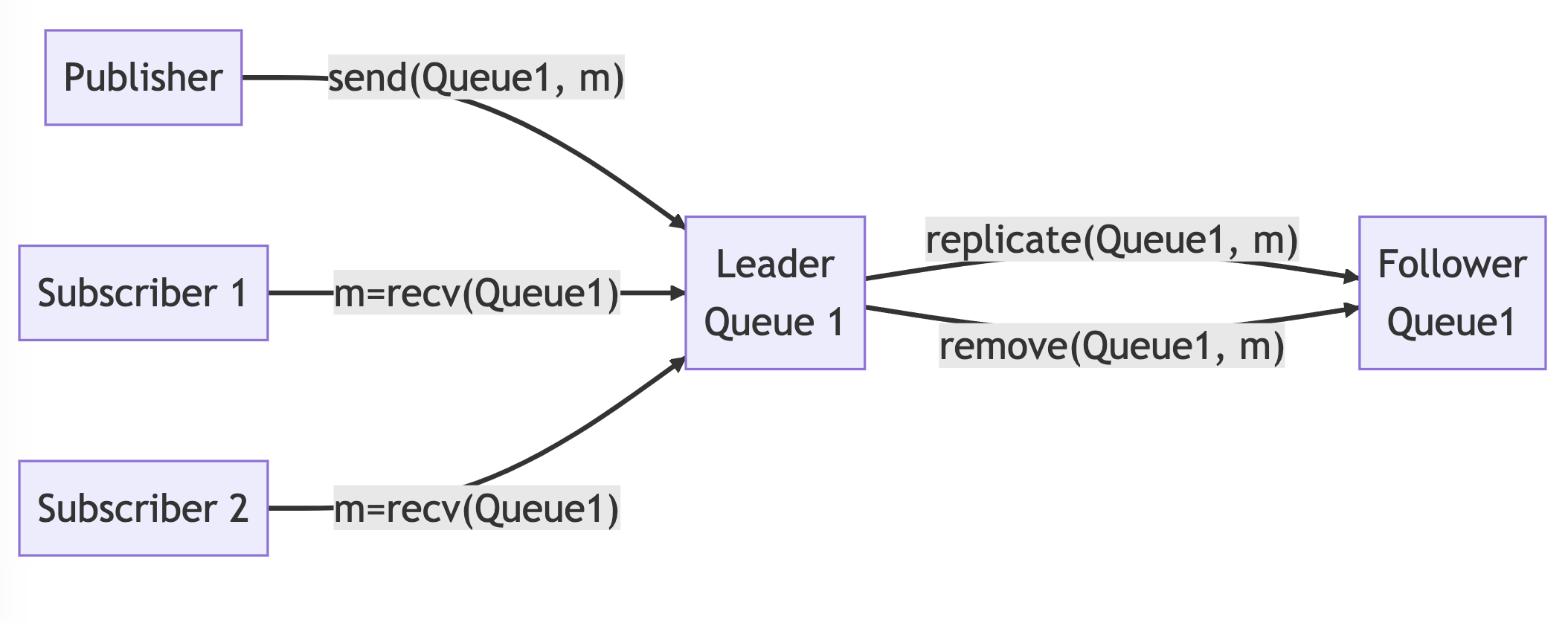
In the event of a leader's failure, producers and consumers will switch to connecting to a follower. This process is called failover, and it is implemented by the broker client library. We will discuss the failure cases that the broker needs to handle for message replication in a future post.
Messaging consumption
There are several methods for consuming messages, but three of the most common are:
- Competing Consumers
- Exactly-Once Processing
- Poison Messages
Competing consumers
Competing consumers are used when a system needs to consume messages as quickly as possible. This pattern involves having multiple consumers, which can be multiple threads within a consumer or multiple consumers on multiple nodes.
This pattern offers several advantages:
- Availability: The replication of consumers ensures that the system remains available.
- Failure handling: Unacknowledged messages are delivered to another consumer.
- Dynamic load balancing: When multiple consumers run on multiple nodes, we can horizontally scale consumers without changing the broker and consumer configuration.
Exactly-once processing
There are two possible sources of duplicate messages:
- Publishers send a message more than once
- Consumers process a message more than once
To achieve idempotency, we use an idempotency key, as discussed in the post on Problems in distributed systems.
When publishers send messages to the broker, they need to use a unique idempotency key. The broker stores this key to detecting message duplication.
If consumers fail to receive or acknowledge the receipt of messages, they need to store the messages' idempotency key.
Poison messages
Poison messages are messages that consumers can't process. For example, in an AI inference service that processes requests, poison messages can be:
- Requests that aren't correctly formatted
- Requests for which the required ML features cannot be computed
The consequences of poison messages can cause consumers to crash or reject poison messages. If message acknowledgment is required, those poison messages remain in the broker or continue to be delivered to other consumers. One possible solution is to limit the number of times a message can be redelivered (typically three to five times). After reaching that limit, the broker moves the poison message to a dead-letter queue. This queue should be monitored to alert and send notifications to engineers. Poison messages in the dead-letter queue should be analyzed to investigate the failure.
Keynotes
- Decoupling, scalability, and fault tolerance are the main benefits of asynchronous messaging
- Pull and push modes are used for message consumption
- Persistent queues are important to prevent message loss in case of system crashes
- Publish-subscribe architecture enables one-to-many messaging delivery
- Leader-follower architecture can be used to replicate brokers on multiple nodes and avoid single points of failure
- Competing consumers and exactly-once processing ensure efficient message consumption and avoid message duplication
- Poison messages are messages that can't be processed and should be handled properly
- Issues such as message duplication, unprocessed messages, and poison messages can arise in asynchronous messaging